Table des matières
- 2.1. Créer une base avec PostGIS
- 2.2. Effectuer des requêtes: le moniteur interactif psql de PostgreSQL
- 2.3. Effectuer des requêtes: PgAdmin III
- 2.4. Exemples de requêtes spatiales I
- 2.4.1. Création de la base et d'une table
- 2.4.2. Ajout de la colonne géométrique à la table - AddGeometryColumn()
- 2.4.3. Objets géométriques spécifiés par l'O.G.C dans PostGIS
- 2.4.4. Insertion d objets géometriques - GeometryFromText()
- 2.4.5. Insertion des données dans la table
- 2.4.6. Question: Quelles sont les aires des objets? - Area2d() -
- 2.4.7. Question: Quel sont les types géométriques des objets? - GeometryType() -
- 2.4.8. Question: Qui est dans le bâtiment 2? - Distance() -
- 2.4.9. Question: Qui est dans le bâtiment 2? - WithIn() -
- 2.4.10. Question: Quel est l'objet géométrique le plus proche du pieton 2? - Min(), Distance() -
- 2.5. Exemples de requêtes spatiales II
- 2.5.1. Chargement des données par SQL
- 2.5.2. Chargement de données par ESRI Shapefiles (shp2pgsql)
- 2.5.3. Question-Pratique: Qu'elle est la version de PostgreSQL?
- 2.5.4. Question-Pratique: Où se trouve notre répertoire de bases de données? - PGDATA -
- 2.5.5. Question-Pratique: Qui sont les utilisateurs de PostgreSQL?
- 2.5.6. Question-Pratique: Quelles sont les infos sur les outils compilés pour PostGIS?
- 2.5.7. Question-Pratique: Quel est le listing des bases de PostreSQL?
- 2.5.8. Question-Pratique: Quelles sont les tables contenues dans la base?
- 2.5.9. Question-Pratique: Utiliser une vue pour simplifier la recherche du listing des tables.
- 2.5.10. Question: Où sont stockées les informations relatives aux données spatiales (métadonnées) des tables avec PostGIS? - table geometry_columns -
- 2.5.11. Question-Pratique: Comment créer une fonction en PLP/PGSQL qui puisse faire le différentiel entre les tables référencées par geometry_columns et toutes les tables contenus dans le schéma public de la base (tables non géospatiales)?
- 2.5.12. Question: Comment sont stockées les données géométriques avec PostGIS?
- 2.5.13. Question: Quelles sont les aires et les périmètres des bâtiments?
- 2.5.14. Question: Qui est dans le bâtiment Résidence des Mousquetaires ?
- 2.5.15. Question: Quelles distances séparent les bâtiments?
- 2.5.16. Question: Combien de points composent chaque objet de la table great_roads? - NumPoints() -
- 2.5.17. Question: Dans la table great_roads, quels sont les premier et dernier point de la Rue Paul Valéry? - StartPoint(), EndPoint() -
- 2.5.18. Question: Quels sont les points d'intersection entre les petites routes (small_roads) et les grandes routes (great_roads)?
- 2.5.19. Question: Quel bâtiment est le plus proche de la personne 2?
- 2.5.20. Question: Quel bâtiment ne contient aucune personne?
- 2.5.21. Question: Quels sont les personnes présentes dans les bâtiments?
- 2.5.22. Question: Combien y-a-t-il de personnes par bâtiments?
- 2.5.23. Question: Quel est l'aire d'intersection entre la rivière et les parcs?
- 2.5.24. Question:Quel bâtiment est contenu dans le parc Mangueret I? - Contains() -
- 2.5.25. Question:Quelles sont les personnes proches de la rivière dans un rayon de 5 mètres? - Buffer () -
- 2.5.26. Question: Quel parc contient un "trou"? - Nrings() -
- 2.5.27. Question: Quels sont les bâtiments que rencontrent la ligne qui relie la personne 5 à la personne 13? - MakeLine() -
- 2.5.28. Application: Utiliser les déclencheurs (triggers) en PL/PGSQL de PostgreSQL pour suivre à la trace la personne 7 quand elle se déplace. Selon sa position, savoir quel est le bâtiment qui lui est le plus proche ou le bâtiment dans lequel elle se trouve?
- 2.6. Cas pratique avec MapServer
- 2.6.1. Importation des communes du Languedoc-Roussillon
- 2.6.2. Afficher les informations relatives au Lambert II Etendu depuis la table spatial_ref_sys
- 2.6.3. Question: Comment faire si on a oublié de préciser l'identifiant de système de projection? - UpdateGeometrySrid() -
- 2.6.4. Création d'index spatiaux Gist, Vacuum de la base
- 2.6.5. Question: Qu'elle est l'étendue géographique de la table communes_lr? - Extent() -
- 2.6.6. Visualisation des données avec MapServer
- 2.6.7. Question: Quelles sont les comunes avoisinantes de Montpellier?, Utilité des index spatiaux - Distance(), && -
- 2.6.8. Utilité des index spatiaux - temps demandé pour exécuter la requête
- 2.6.9. Créer une table communes_avoisinantes correspondant aux communes avoisinantes de MONTPELLIER, extraite et conforme à la structure de la table communes_lr, exploitable par MapServer.
- 2.6.10. Requête 1: Qu'elle est l'intersection entre MONTPELLIER et les communes de LATTES et de JUVIGNAC?- Intersection()- Que vaut cette géométrie en SVG? - AsSVG(),
- 2.6.11. Requête 2: Qu'elle est la commune ayant la plus petite aire?
- 2.6.12. Mapfile générale pour la table communes_avoisinantes et les deux requêtes précédentes
- 2.6.13. Exercice: Obtenir une table departements_lr qui contient les contours départmentaux du Languedoc-Roussillon à partir de la table communes_lr
- 2.6.14. Exercice: Trouver les communes du Gard et de l'Aude qui sont limitrophes à l'Hérault et les afficher grâce à MapServer.
Mon but ici n'est pas de m'étendre sur l'utilisation de PostGIS mais juste montrer comment créer une base avec PostGIS et un éventail de requêtes possibles avec PostGIS et un cas pratique d'utilisation avec MapServer. Nous commencerons donc par voir comment créer une base ayant les fonctionnalités de PostGIS.
Deux séries de requêtes seront ensuite abordées. La première consiste en un survol rapide des possibiltés de PostGIS. Elle a plutôt un aspect ludique -LOL - La deuxième tente de voir plusieurs aspects possibles: importation de données, comportement de PostGIS, requêtes jugées pertinentes. Pour ces deux séries, les index spatiaux Gist ne seront pas abordés -car ici le nombre de données n'est pas assez volumineux-. Des clins d'oeil à MapServer sont fournis dans la deuxième série parfois. Ces derniers sont mis ici en illustration afin de montrer la requête adéquate pour faire la liaison entre PostGIS et MapServer.
L'utilisation avec MapServer - qui clôture ce chapitre - est un cas pratique où l'on doit dans un premier temps importer des données SIG réelles et extraire de ces données une nouvelle table qui puisse être exploitable par MapServer. Dans un second temps, il est demandé de créer de nouvelles données à partir des premières données, de les afficher ensuite dans MapServer. Celà est fait dans l'optique de montrer le travail qui peut attendre un administrateur PostgreSQL/PostGIS.
Note
L'installation de MapServer sur Debian ou GNU/Linux n'est pas abordée ici. Merci de vous référer à la documentation que vous trouverez sur le site de postgis.fr pour une éventuelle installation.
La création d'une base - par exemple nommée madatabase - se fait en tapant depuis un terminal tout en étant logué sous postgres:
createdb madatabase createlang plpgsql madatabase psql -d madatabase -f /usr/local/pgsql/share/lwpostgis.sql psql -d madatabase -f /usr/local/pgsql/share/spatial_ref_sys.sql
Examinons en détail les diverses commandes utilisées:
La première (createdb ...) est la commande utilisée pour créer une base madatabase.
PostGIS est écrit en C/C++ Les fonctions spatiales sont stockées dans une librairie liblwgeom.so.1.1. PostgreSQL accède à ces fonctions à condition de lui spécifier le langage PL/PGSQL. La seconde commande permet donc de doter notre base de ce langage.
Les définitions des diverses fonctions spatiales sont stockées dans le fichier lwpostgis.sql que doit accepter notre base. On charge les fonctions spatiales de PostGIS grâce à la troisième commande. On assure donc un pont entre notre base de données et la librairie liblwgeom.so.1.1
Il est souvent utile de pouvoir passer d'un système de projection à un autre et même impératif de se doter des divers systèmes de projections connus (Lambert I Carto, Lambert II Etendu ...).La quatrième commande nous permet de se doter des divers systèmes. Ces derniers sont stockés dans une table par le biais du chargement du fichier spatial_ref_sys.sql - nom que portera aussi la table des systèmes de projection -.
Note
Comme il existe une variable d'environnement propre à PostgreSQL PGHOME - qui ici vaut pour rappel /usr/local/pgsql -, on accède à sa valeur en la préfixant par $
createdb madatabase createlang plpgsql madatabase export PGHOME=/usr/local/pgsql psql -d madatabase -f $PGHOME/share/lwpostgis.sql psql -d madatabase -f $PGHOME/share/spatial_ref_sys.sql
psql - contenu dans toute distibrution même celle que nous avons compilée et installée - est le moniteur interactif de PostgreSQL. Il permet en outre de faire des requêtes adresser directement à un serveur PostgreSQL. On se connecte à une base mabasededonnees en faisant
psql mabasededonnees
Note
Pour sortir du moniteur interactif, il suffit de saisir \q
PgAdmin est de loin le meilleur outil libre qui soit pour effectuer ses requêtes sous PostgreSQL. Mais il peut faire bien mieux. Le site de pgadmin est http://www.pgadmin.org
Note
Pour ma part c'est avec psql qu'aura lieu les requêtes de ce chapitre.Sur le site de PgAdmin, un paquet .deb existe déjà pour debian - merci de suivre les informations détaillées sur le site, si vous souhaitez l'installer.
Ici nous allons commencer par créer une base de données testgis que nous allons ensuite peupler par quelques données basiques. Pour la création de la base, reportez-vous à la première section de ce chapitre, ce qui depuis un terminal devrait nous donner comme commandes à exécuter
createdb testgis createlang plpgsql testgis psql -d testgis -f /usr/local/pgsql/share/lwpostgis.sql psql -d testgis -f /usr/local/pgsql/share/spatial_ref_sys.sql
Connectons-nous maitenant à notre base testgis grâce à la commande suivante:
psql testgis
Peuplons maintenant notre base par quelques données génériques. Pour cela, créons une petite table test en saisissant
CREATE TABLE test (id serial PRIMARY KEY,genre text);
Pour l'instant notre table est vide, nous allons lui ajouter une troisième colonne où seront stockées nos données géométriques. Nous aurons recours pour cela à la fonction AddGeometryColumn() de PostGIS dont la synthaxe générale est
AddGeometryColumn( [Table],
[Colonne_Geometrique],
[SRID],
[Type_Geometrie],
[Dimension]);où
[Table] est le nom de la table à laquelle doit être ajoutée la colonne géométrique;
[Colonne_Geometrique] est le nom de la colonne géométrique;
[Type_Geometrie] est le le type de géométrie possible:
[SRID] est l'identifiant spatial de projection selon le système de projection choisi. A titre d'exemple pour le Lambert II Carto Etendu, srid=27852;
[Dimension] est la dimension des objets géométriques 2D ou 3D ou 4D;
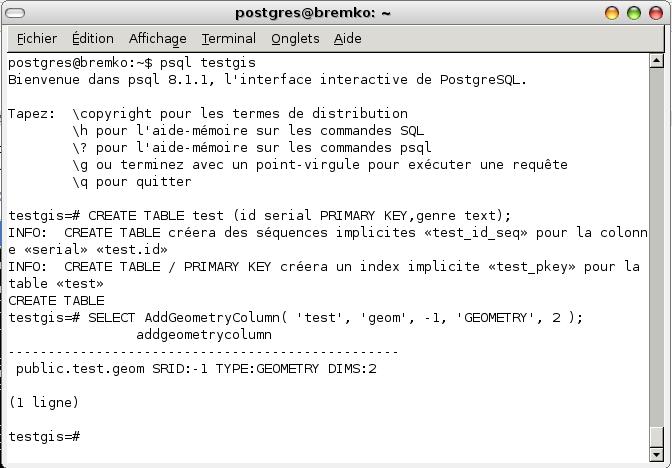
Dans notre cas, nous saisirons
SELECT AddGeometryColumn( 'test', 'geom', -1, 'GEOMETRY', 2 );
Nous avons avec cette requête ajouté la colonne géométrique geom ([Colone_Geometrique]) à la table test ([Table]). Comme nous utilisons ici aucun système de projection référencé, - nous restons donc dans le plan 2D orthonormal par défaut - nous précisons juste srid=-1([SRID]). Le type de données géométriques que nous souhaitons enregistrer peut-être de n'importe quel type. Nous préciserons donc par défaut GEOMETRY ([Type_Geometrie]). Nous sommes en 2D ([Dimension]).
Note
Il aurait été tout à fait possible de créer la table test en faisant directement
CREATE TABLE test (id serial PRIMARY KEY,genre TEXT,geom GEOMETRY);
Mais il y aurait alors eu un perte concernant les méta-données sur les objets géométriques concernant le type, le srid, la dimension. Il est donc préférable d'avoir recours à la fonction AddGeometryColumn() pour pouvoir tirer profit de ces métadonnées.
PostGIS supporte amplement les objets géométriques définis par l'O.G.C (Open GIS COnsortium). A titre d'exemple, nous citerons donc:
POINT;
LINESTRING;
POLYGON;
MULTIPOINT;
MULTILINETRING;
MULTIPOLYGON;
GEOMETRYCOLLECTION
Insérons maintenant quelques objets dans notre table
L'insertion d'objets géométriques peut par exemple avoir lieu en ayant recours à la fonction GeometryFromText() dont la synthaxe générale est
GeometryFromText( [Objet_Geometrique],
[SRID])où
[Objet_Geometrique] est l'objet à insérer est qui est "humainement lisible", j'entends par humainement lisible au sens qu'il est au format WKT (Well-Known Text);
[SRID] l'identifiant de projection qui doit être conforme à celui choisi la colonne géométrique (ici colone geom avec srid=-1).
Note
Il existe aussi une autre définition de la fonction GeometryFromText(). Il est aussi possible d'utiliser les fonctions GeomFromText() ou GeomFromEWKT() etc...Par exemple pour insérer l'objet 'POINT(10 70)' ayant comme identifiant de projection SRID=-1, les 4 fonctions suivantes sont équivalentes
SELECT GeometryFromText( 'POINT(10 70)', -1 ); SELECT GeometryFromText('SRID=-1;POINT(10 70)'); SELECT GeomFromText('SRID=-1;POINT(10 70)'); SELECT GeomFromEWKT('SRID=-1;POINT(10 70)');
Insérons maintenant quelques objets géométriques. Ici les commandes sont à saisir au fur et à mesure pour chaque commande de type INSERT INTO...;
INSERT INTO test VALUES ( 1, 'pieton 1', GeometryFromText( 'POINT(10 70)', -1 ) ); INSERT INTO test VALUES ( 2, 'pieton 2', GeometryFromText( 'POINT(30 30)', -1 ) ); INSERT INTO test VALUES ( 3, 'batiment 1', GeometryFromText( 'POLYGON((10 10,40 20,35 8,12 4,10 10))', -1 ) ); INSERT INTO test VALUES ( 4, 'batiment 2', GeometryFromText( 'POLYGON((10 40,20 30,30 40,40 35,50 60,35 80,20 60,10 40))', -1 ) ); INSERT INTO test VALUES ( 5, 'batiment 3', GeometryFromText( 'POLYGON((10 95,20 95,20 135,10 135,10 95))', -1 ) ); INSERT INTO test VALUES ( 6, 'pieton 3', GeometryFromText( 'POINT(35 70)', -1 ) ); INSERT INTO test VALUES ( 7, 'pieton 4', GeometryFromText( 'POINT(35 60)', -1 ) ); INSERT INTO test VALUES ( 8, 'bordure 1 route', GeometryFromText( 'LINESTRING(1 85,50 85)', -1 ) ); INSERT INTO test VALUES ( 9, 'bordure 2 route', GeometryFromText( 'LINESTRING(1 92,50 92)', -1 ) );
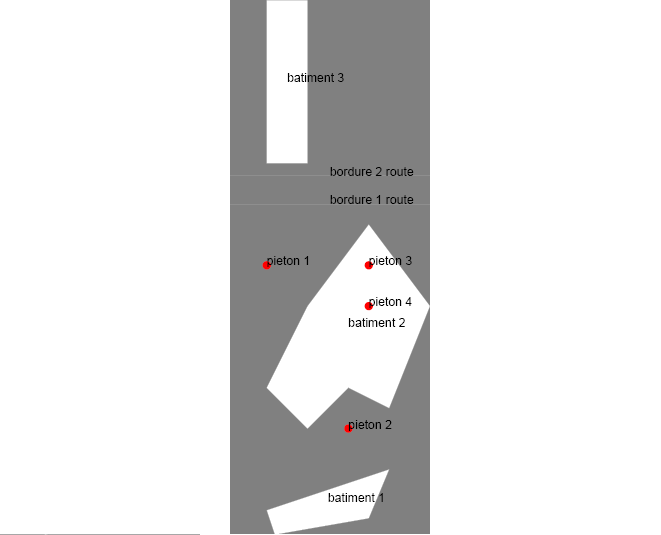
Le visuel de la table test est le suivant
Les instructions/requêtes suivantes doivent être saisie dans le terminal de psql.
Note
Il est tout à fait possible de saisir les requêtes sans entrer dans le terminal de psql.Pour cela, il suffit de saisir
psql -d testgis -c "VOTRE_REQUETE"
La fonction Area2d() renvoie les aires des objets et la
testgis=# SELECT id,genre,Area2d(geom) FROM test; id | genre | area2d ----+-----------------+-------- 1 | pieton 1 | 0 2 | pieton 2 | 0 3 | batiment 1 | 228 4 | batiment 2 | 1050 5 | batiment 3 | 400 6 | pieton 3 | 0 7 | pieton 4 | 0 8 | bordure 1 route | 0 9 | bordure 2 route | 0 (9 rows)
Il faut pour cela utiliser la fonction GeometryType()
testgis=# SELECT id,genre,geometrytype(geom) FROM test; id | genre | geometrytype ----+-----------------+-------------- 1 | pieton 1 | POINT 2 | pieton 2 | POINT 3 | batiment 1 | POLYGON 4 | batiment 2 | POLYGON 5 | batiment 3 | POLYGON 6 | pieton 3 | POINT 7 | pieton 4 | POINT 8 | bordure 1 route | LINESTRING 9 | bordure 2 route | LINESTRING (9 rows)
Ici, il suffira par exemple de trouver les objets dont le champs genre commence par pieton... et de déterminer les objets dont la distance à ce bâtiment est nulle:
testgis=# SELECT genre AS pietons_dans_batiment_2 FROM test
WHERE
Distance((SELECT geom FROM test WHERE genre LIKE 'batiment 2'),test.geom)=0
AND
genre LIKE 'pieton%';
pietons_dans_batiment_2
-------------------------
pieton 3
pieton 4
(2 rows)
Ici, je propose par rapport à la première façon de faire d'utiliser la fonction WithIn(A,B) qui permet de savoir si A est contenu dans B
testgis=# SELECT genre AS pietons_dans_batiment_2 FROM test
WHERE
WithIn(test.geom,(SELECT geom FROM test WHERE genre LIKE 'batiment 2'))
AND
genre like 'pieton%';
pietons_dans_batiment_2
-------------------------
pieton 3
pieton 4
(2 rows)Pour cette question, nous aurons recours à la fonction Min() et à la fonction Distance()
testgis#SELECT q.genre FROM test z,test q WHERE z.genre LIKE 'pieton 2' AND Distance(z.geom,q.geom)=(SELECT min(foo.valeur) FROM (SELECT h.genre AS nom,distance(t.geom,h.geom) AS valeur FROM test t, test h WHERE t.genre LIKE 'pieton 2' AND h.genre<>'pieton 2') foo); genre ------------ batiment 2 (1 row)
Plusieurs formulations sont possibles pour les requêtes, on aurait ici pu aussi proposer la requête suivante
SELECT b.genre,Distance(a.geom,b.geom) FROM test a,test b WHERE a.genre='pieton 2' AND a.genre!=b.genre ORDER BY distance ASC limit 1;
qui donnera le résultat suivant attendu
genre | distance ------------+------------------ batiment 2 | 7.07106781186548 (1 ligne)
Je ne propose ici que des exemples de bases de requêtes spatiales. Pour tirer un meilleur profit possible des fonctions spatiales, je ne serais vous conseiller la documentation sur le site de PostGIS réalisé par Paul RAMSEY. Pour de plus amples informations sur PostgreSQL, n'hésitez pas non plus à regarder dans le répertoire /usr/local/pgsql/doc/html.
Pour charger le contenu du fichier sql suivant, copiez-le dans un fichier madatabase.sql et depuis un terminal, tapez
psql -d mdatabase -f madatabase.sql
Le contenu du script madatabase.sql [1]est
/*
================================================================================
TECHER Jean David
Script SQL 'madatabase.sql' à utiliser avec la base madatabase
Toutes les tables ont la même struture à savoir les champs suivants
- id : identifiant pour l'objet
- data: qui est la donnée attributaire de l'objet
- the_geom: qui est l'objet spatial
Il y a en tout 6 tables (voir commentaires pour chaque table).
================================================================================
*/
/*
================================================================================
- commentaires:...... .... -
================================================================================
*/
/*
================================================================================
Cette fonction écrite en SQL permet de tester si une table existe et de
l'effacer le cas échéant.
================================================================================
*/
CREATE OR REPLACE FUNCTION drop_table_if_exists(text, bool) RETURNS text AS '
DECLARE
opt text;
rec record;
BEGIN
IF $2 THEN
opt := '' CASCADE'';
ELSE
opt := '''';
END IF;
IF NULLVALUE($1) THEN
RETURN ''ATTENTION: Table non trouvée'';
ELSE
SELECT INTO rec tablename FROM pg_tables WHERE tablename like $1;
IF FOUND THEN
EXECUTE ''DROP TABLE '' || $1 || opt;
RETURN ''Effacement de la table ''|| $1 || ''...OK'';
END IF;
END IF;
RETURN ''ATTENTION: Table ''|| $1 || '' non trouvée'';
END;
' LANGUAGE 'plpgsql';
/*
================================================================================
On utilise la fonction pour effacer les tables éventuelles.
Fonction utile au cas où on devrait recharger ce fichier.
On évitera aussi d'effacer les tables geometry_columns et spatial_ref_sys
================================================================================
*/
SELECT tablename,drop_table_if_exists(tablename,false)
FROM pg_tables
WHERE (tablename NOT LIKE 'pg_%')
AND (tablename NOT LIKE 'spatial_ref_sys' )
AND (tablename NOT LIKE 'sql%' )
AND (tablename NOT LIKE 'geom%' );
/*
================================================================================
Table pietions
Certains des piétions sont dans certains des bâtiments.
================================================================================
*/
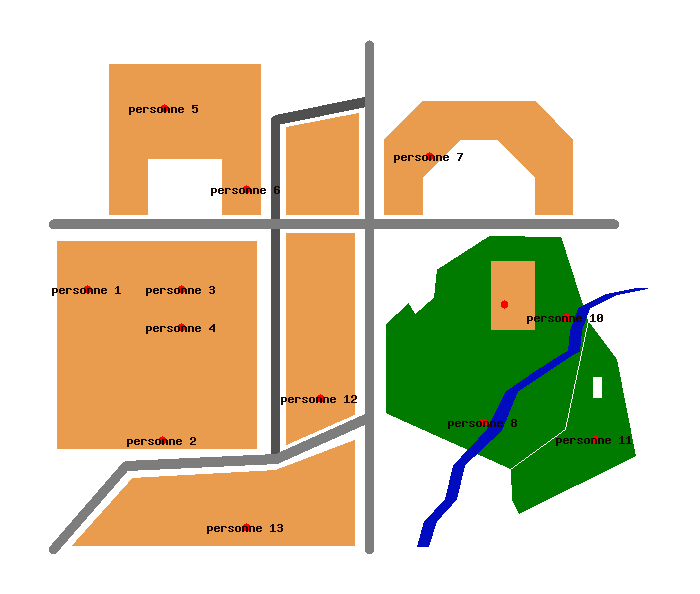
CREATE TABLE personnes (
id serial PRIMARY KEY,
data text);
SELECT AddGeometryColumn('','personnes','the_geom','-1','POINT',2);
INSERT INTO personnes VALUES ( 1, 'personne 1', GeometryFromText( 'POINT(10 70)', -1 ) );
INSERT INTO personnes VALUES ( 2, 'personne 2', GeometryFromText( 'POINT(30 30)', -1 ) );
INSERT INTO personnes VALUES ( 3, 'personne 3', GeometryFromText( 'POINT(35 70)', -1 ) );
INSERT INTO personnes VALUES ( 4, 'personne 4', GeometryFromText( 'POINT(35 60)', -1 ) );
INSERT INTO personnes VALUES ( 5, 'personne 5', GeometryFromText( 'POINT(30.54 118.28)', -1 ) );
INSERT INTO personnes VALUES ( 6, 'personne 6', GeometryFromText( 'POINT(52.36 96.73)', -1 ) );
INSERT INTO personnes VALUES ( 7, 'personne 7', GeometryFromText( 'POINT(100.94 105.44)', -1 ) );
INSERT INTO personnes VALUES ( 8, 'personne 8', GeometryFromText( 'POINT(115.16 34.81)', -1 ) );
INSERT INTO personnes VALUES ( 9, 'personne 9', GeometryFromText( 'POINT(120.89 66.23)', -1 ) );
INSERT INTO personnes VALUES ( 10, 'personne 10', GeometryFromText( 'POINT(137.40 62.56)', -1 ) );
INSERT INTO personnes VALUES ( 11, 'personne 11', GeometryFromText( 'POINT(144.97 30.23)', -1 ) );
INSERT INTO personnes VALUES ( 12, 'personne 12', GeometryFromText( 'POINT(72.04 41.23)', -1 ) );
INSERT INTO personnes VALUES ( 13, 'personne 13', GeometryFromText( 'POINT(52.32 6.84)', -1 ) );
/*
================================================================================
Table buildings:
J'ai opté pour des noms classiques de bâtiments administratifs
================================================================================
*/
CREATE TABLE buildings (
id serial PRIMARY KEY,
data text);
SELECT AddGeometryColumn('','buildings','the_geom','-1','POLYGON',2);
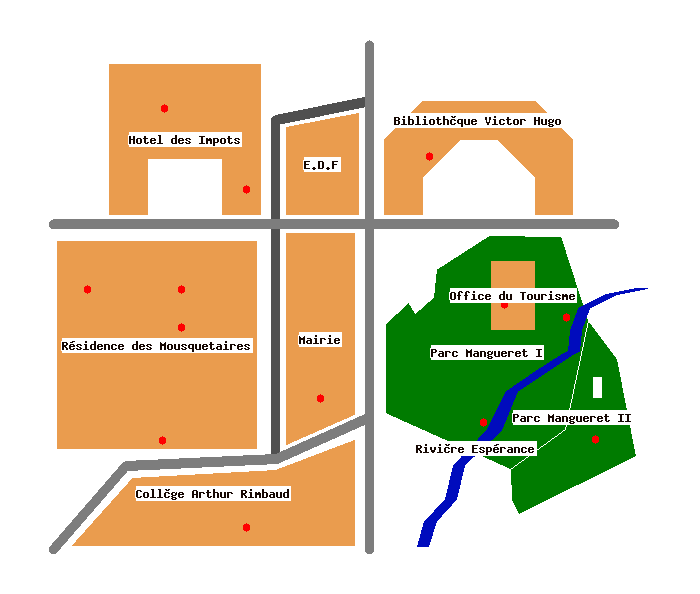
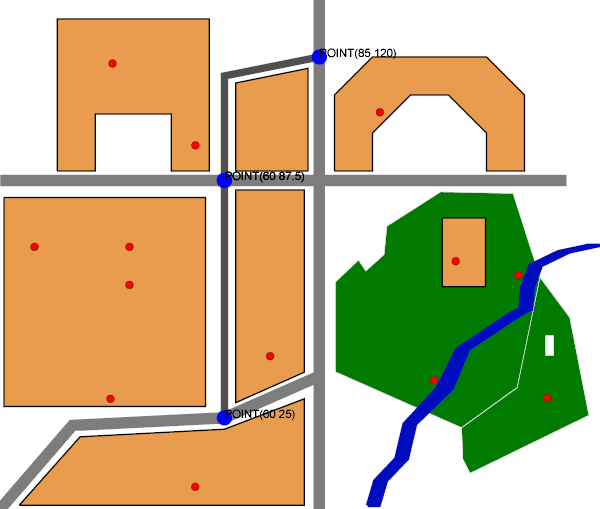
INSERT INTO buildings VALUES ( 1, 'Collège Arthur Rimbaud',
GeometryFromText( 'POLYGON((6 2,81 2,81 30,60 22,22 20,6 2))', -1 ) );
INSERT INTO buildings VALUES ( 2, 'Résidence des Mousquetaires',
GeometryFromText( 'POLYGON((2 83,55 83,55 28,2 28,2 83))', -1 ) );
INSERT INTO buildings VALUES ( 3, 'Hotel des Impots',
GeometryFromText( 'POLYGON((16 90,26 90,26 105,46 105,
46 90,56 90,56 130,16 130,16 90))', -1 ) );
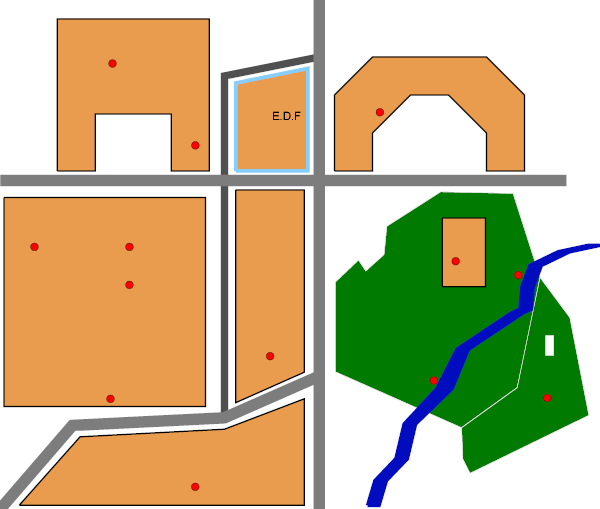
INSERT INTO buildings VALUES ( 4,'E.D.F',
GeometryFromText( 'POLYGON((63 90,82 90,82 117,63 113.15,63 90))', -1 ) );
INSERT INTO buildings VALUES ( 5,'Bibliothèque Victor Hugo',
GeometryFromText( 'POLYGON((89 90,99 90,99 100,109 110,119 110,129 100,
129 90,139 90,139 110,129 120,99 120,89 110,89 90))', -1 ) );
INSERT INTO buildings VALUES ( 6, 'Mairie',
GeometryFromText( 'POLYGON((63 85,81 85,81 37,63 29,63 85))', -1 ) );
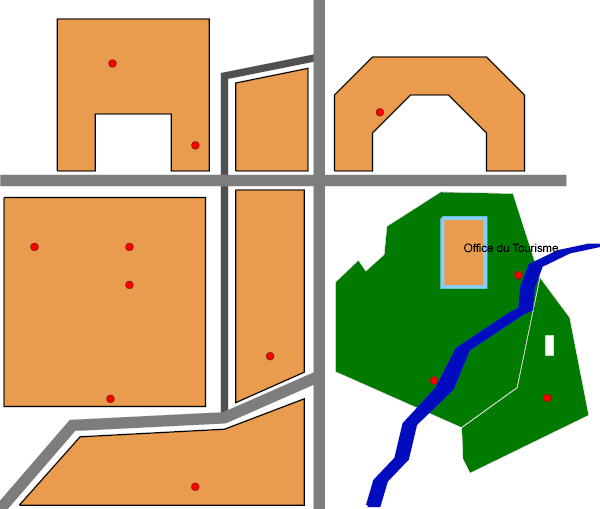
INSERT INTO buildings VALUES ( 7, 'Office du Tourisme',
GeometryFromText( 'POLYGON((117.36 77.6,128.71 77.60,128.71 59.49,
117.36 59.49,117.36 77.6))', -1 ) );
/*
================================================================================
Tables small_roads:
Il n'y en a que deux.
================================================================================
*/
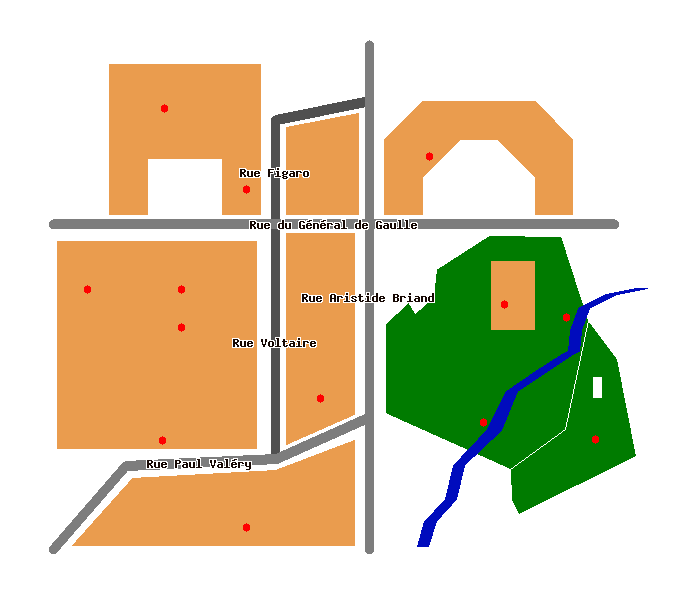
CREATE TABLE small_roads (
id serial PRIMARY KEY,
data text);
SELECT AddGeometryColumn('','small_roads','the_geom','-1','LINESTRING',2);
INSERT INTO small_roads VALUES (1, 'Rue Figaro',
GeometryFromText( 'LINESTRING(60 87.5,60 115,85 120)', -1 ) );
INSERT INTO small_roads VALUES (2, 'Rue Voltaire',
GeometryFromText( 'LINESTRING(60 87.5,60 25)', -1 ) );
/*
================================================================================
Tables great_roads
Il y en a 3. Les grandes routes gardent leur nom malgré un ou plusieurs
croisement avec d'autres routes
================================================================================
*/
CREATE TABLE great_roads (
id serial PRIMARY KEY,
data text);
SELECT AddGeometryColumn('','great_roads','the_geom','-1','LINESTRING',2);
INSERT INTO great_roads VALUES (1, 'Rue Paul Valéry',
GeometryFromText( 'LINESTRING(1 1,20 23,60 25,85 36)', -1 ) );
INSERT INTO great_roads VALUES ( 2, 'Rue du Général de Gaulle',
GeometryFromText( 'LINESTRING(1 87.5,150 87.5)', -1 ) );
INSERT INTO great_roads VALUES ( 3, 'Rue Aristide Briand',
GeometryFromText( 'LINESTRING(85 1,85 135)', -1 ) );
/*
================================================================================
Table parc
Il y en a deux portant le nom générique de Mangueret. Le premier parc est
traversé par la rivière et conteint le bâtiment de l'Office du Tourisme.
Le deuxième parc contient une aire adminitrative en réaménagement rachétée
par la mairie. Le temps de la construction cette aire ne fait donc par partie
du parc. Soit un trou dans le polygone modélisant ce parc.
================================================================================
*/
CREATE TABLE parcs (
id serial PRIMARY KEY,
data text);
SELECT AddGeometryColumn('','parcs','the_geom','-1','POLYGON',2);
INSERT INTO parcs VALUES (1,'Parc Mangueret I',
GeometryFromText( 'POLYGON((89.19 37.11,89.19 60.73,
95.31 66.56,97.23 63.68,102.03 68,102.75 75.44,116.91 84.5,136 84.08,
143.08 62,140.92 50,137.08 32.95,122.43 22.39,89.19 37.11))',-1));
INSERT INTO parcs VALUES (2,'Parc Mangueret II',
difference(
GeometryFromText( 'POLYGON((143.08 62,150.94 51.41,155.96 25.66,
124.64 10.38,122.78 14.09,122.43 22.39,137.08 32.95,143.08 62))',-1),
GeometryFromText( 'POLYGON((144.55 46.64,146.68 46.64,146.68 41.46,
144.55 41.46,144.55 46.64))',-1)));
/*
================================================================================
Table rivers
================================================================================
*/
CREATE TABLE rivers (
id serial PRIMARY KEY,
data text);
SELECT AddGeometryColumn('','rivers','the_geom','-1','POLYGON',2);
INSERT INTO rivers VALUES (1,'Rivière Espérance',
GeometryFromText( 'POLYGON((97.71 1.98,99.63 8.46,105.15 14.23,107.31 23.35,
115.95 32.71,121.23 43.03,129.15 48.31,
135.64 52.64,137.80 53.60,138.28 59.36,
140.44 65.12,147.88 68.72,155.80 70.40,158.80 70.40,
150.88 68.72,143.44 65.12,141.28 59.36,140.80 53.60,138.64 52.64,
132.15 48.31,124.23 43.03,119.95 32.71,110.31 23.35,108.15 14.23,
102.63 8.46,100.71 1.98,97.71 1.98))',-1));
/*
================================================================================
- Fonction permettant de créer des index spatiaux -
On va commencer par vérifier quel est le nom de la colonne géométrique
dans la table demandée (par défaut = the_geom) ...Il faut bien sûr que ce nom soit
préciser dans la table geometry_columns.
Cette fonction permet surtout d'alléger la commande de création d'indexation spatiale
================================================================================
*/
CREATE OR REPLACE FUNCTION Create_Gis_Index(text) RETURNS text AS '
DECLARE
rec record;
BEGIN
SELECT INTO rec f_geometry_column FROM geometry_columns WHERE f_table_name like $1;
IF FOUND THEN
EXECUTE ''CREATE INDEX '' || $1 || ''_index_spatial ON ''|| $1 ||
'' USING gist(''|| rec.f_geometry_column || '' gist_geometry_ops)'';
RETURN ''Index Spatial sur '' || $1 || ''...OK'';
END IF;
RETURN ''Impossible de créer index spatial sur '' || $1 ;
END;
' LANGUAGE 'plpgsql';
/*
================================================================================
- Création des index spatiaux -
================================================================================
*/
SELECT Create_Gis_Index(tablename)
FROM pg_tables
WHERE (tablename NOT LIKE 'pg_%')
AND (tablename NOT LIKE 'spatial_ref_sys' )
AND (tablename NOT LIKE 'sql%' )
AND (tablename NOT LIKE 'geom%' )
ORDER BY tablename;
/*
================================================================================
- Vérification de la création des index spatiaux -
================================================================================
*/
\di *_index_spatial
/*
================================================================================
- Table de permettant de gérer MapServer -
================================================================================
*/
CREATE TABLE mapserver_desc (
ms_gid serial PRIMARY KEY,
ms_table text,
ms_libelle text,
ms_name text,
ms_labelitem text,
ms_color text,
ms_outlinecolor text,
ms_symbol text
);
INSERT INTO mapserver_desc values (0,'small_roads', 'Petite routes',
'small_roads','data','80 80 80','80 80 80',NULL);
INSERT INTO mapserver_desc values (1,'great_roads','Grandes routes',
'great_roads','data','125 125 125','125 125 125',NULL);
INSERT INTO mapserver_desc values (2,'parcs','Parcs publiques',
'parcs','data','0 123 0','0 123 0',NULL);
INSERT INTO mapserver_desc values (3,'rivers','Rivière',
'rivers','data','0 12 189','0 12 189',NULL);
INSERT INTO mapserver_desc values (4,'buildings', 'Bâtiments',
'buildings','data','234 156 78','234 156 78',NULL);
INSERT INTO mapserver_desc values (5,'personnes', 'personnes',
'personnes','data',NULL,'0 0 255','circle');Nous allons supposer dans cette sous-sections que nous disposons des mêmes sources de données que celles ci-dessus. Ces dernières cette fois-ci au lieux d'être stockées au format sql sont ici stockées au format .shp. Chaque table est ainsi stockées dans un fichier .shp - avec les fichiers auxiliaires adéquates (.dbf, .shx....).
Note
Les fichiers en question sont disponibles à http://www.postgis.fr/download/win32/shp.zip. Décompressez ce fichier(unzip shp.zip) et double-cliquez sur le fichier batch import.bat pour les charger dans la base. N'hésitez pas à ouvrir pour l'étudier par rapport aux explications qui suivent sur shp2pgsql.exe. SI vous n'avez pas pour le moment importé le fichier madatabase.sql (cf. "Chargement en SQL") ouvrez alors ce fichier et remplacez l'option "-dD" en "-D".
PostGIS est livré avec un convertisseur shp2pgsql qui permet d'importer directement - à la volée - les données fournies dans un fichier .shp. Pour de meilleurs informations sur ce convertisseur, il suffit de saisir
shp2pgsql --help
qui vous renverra en sortie
shp2pgsql: illegal option -- -
RCSID: $Id: shp2pgsql.c,v 1.104 2005/11/01 09:25:47 strk Exp $
USAGE: shp2pgsql [<options>] <shapefile> [<schema>.]<table>
OPTIONS:
-s <srid> Set the SRID field. If not specified it defaults to -1.
(-d|a|c|p) These are mutually exclusive options:
-d Drops the table , then recreates it and populates
it with current shape file data.
-a Appends shape file into current table, must be
exactly the same table schema.
-c Creates a new table and populates it, this is the
default if you do not specify any options.
-p Prepare mode, only creates the table
-g <geometry_column> Specify the name of the geometry column
(mostly useful in append mode).
-D Use postgresql dump format (defaults to sql insert
statments.
-k Keep postgresql identifiers case.
-i Use int4 type for all integer dbf fields.
-I Create a GiST index on the geometry column.
-w Use wkt format (for postgis-0.x support - drops M - drifts coordinates).
-N <policy> Specify NULL geometries handling policy (insert,skip,abort)Avec shp2pgsql, la ligne de commande la plus utilisée est
shp2pgsql -D -I shapefile nom_table | psql base_de_donnees
où l'option
-D permet d'importer les données sous forme de COPY au lieu de INSERT. Ce qui est beaucoup plus rapide au niveau de l'importation des données
-I permet de créer automatiquement un index spatial pour les données géométriques importées
shapefile est le chemin d'accès complet vers le shapefile
nom_table est le nom que vous souhaiteriez donner à votre table
Dans notre cas nous allons supposer que tous nos shapefiles sont dans le répertoire c:\Mes donnees SIG\shp et que les noms respectives des tables seront le même que celui des fichiers .shp. Le contenu en fichier .shp du répertoire en question est obtenu par la commande ls depuis un terminal
$ ls *.shp buildings.shp great_roads.shp parcs.shp personnes.shp rivers.shp small_roads.shp
Pour nos importations, il nous suffira de faire depuis un terminal
pour le chargement:
for i in `ls *.shp`;\ > do \ > table=`basename $i | cut -d '.' -f 1`;\ > shp2pgsql -dDI $i $table | psql madatabase;\ > done
ou en un peu plus subtil:
for i in $(find . | grep shp);do shp2pgsql -dDI $i $(basename $i .shp) | psql madatabase;done
qui nous renverra
Shapefile type: Polygon
Postgis type: MULTIPOLYGON[2]
dropgeometrycolumn
------------------------------------------------
public.buildings.the_geom effectively removed.
(1 row)
DROP TABLE
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "buildings_gid_seq" for serial column "buildings.gid"
NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "buildings_pkey" for table "buildings"
CREATE TABLE
addgeometrycolumn
-------------------------------------------------------------------------------------
public.buildings.the_geom SRID:-1 TYPE:MULTIPOLYGON DIMS:2
geometry_column fixed:0
(1 row)
CREATE INDEX
COMMIT
.
.
.
Shapefile type: Arc
Postgis type: MULTILINESTRING[2]
dropgeometrycolumn
--------------------------------------------------
public.small_roads.the_geom effectively removed.
(1 row)
DROP TABLE
BEGIN
NOTICE: CREATE TABLE will create implicit sequence "small_roads_gid_seq" for serial column "small_roads.gid"
NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "small_roads_pkey" for table "small_roads"
CREATE TABLE
addgeometrycolumn
------------------------------------------------------------------------------------------
public.small_roads.the_geom SRID:-1 TYPE:MULTILINESTRING DIMS:2
geometry_column fixed:0
(1 row)
CREATE INDEX
COMMITLe message CREATE INDEX confirme la création des index spatiaux Gist, 'addgeometrycolumn ' confirme aussi l'insertion des données spatiales.
Il suffit pour cela d'utiliser la fonction interne de PostgreSQL: Version()
select version()
qui nous renvoit
version ------------------------------------------------------------------------------------------ PostgreSQL 8.1.1 on i686-pc-mingw32, compiled by GCC gcc.exe (GCC) 3.4.2 (mingw-special) (1 ligne)
On peut aussi utiliser la requête suivante
SHOW server_version
qui nous renvoit
server_version ---------------- 8.1.1 (1 ligne)
Note
Le numéro de version peut-être aussi obtenu en tapant depuis un terminal :
pg_config --version
La requête suivante
SHOW data_directory
confime ce que nous avons choisi comme valeur pour la variable d'environnement PGDATA[2]
data_directory ---------------------------------------- /mnt/pgdata (1 ligne)
Je ne fais pas ici de distinction entre les super-utilisateurs et les utilisateurs courants de PostgreSQL. En un mot, je ne m'occuperais pas ici des droits attibués (création de base, ajout d'utilisateur etc...). Pour simplifier, on dira que la requête est
select usename from pg_user order by usename
qui nous renvoit
usename ---------- postgres (1 ligne)
On obtient de meilleurs informations en faisant directement:
psql -d template1 -c "\du"
Liste des rôles Nom du rôle | Superutilisateur | Crée un rôle | Crée une base | Connexions | Membre de -------------+------------------+--------------+---------------+-------------+----------- postgres | oui | oui | oui | sans limite | (3 lignes)
La requête suivante
select postgis_full_version();
nous renverra comme réponse
postgis_full_version ---------------------------------------------------------------------------------- POSTGIS="1.1.2" GEOS="2.2.1-CAPI-1.0.1" PROJ="Rel. 4.4.9, 29 Oct 2004" USE_STATS (1 ligne)
Ce qui prouve bien que PostGIS 1.1.2, Geos 2.2.1 et Proj 4.4.9 ont bien compilés.
cela se fait en faisant la requête suivante
SELECT pg_database.datname
FROM pg_database, pg_user
WHERE pg_database.datdba = pg_user.usesysid
AND pg_database.datname not
LIKE 'template%' order by datnamequi ici renvoit
datname ----------- madatabase testgis (2 lignes)
On obtient aussi les mêmes informations en faisant psql -l.
La requête suivante
select tablename as nom_table from pg_tables where (tablename not like 'pg_%') and (tablename not like 'spatial_ref_sys' ) and (tablename not like 'sql_%' ) and (tablename not like 'geom%' ) order by tablename; ;
nous renverra comme réponse
nom_table ---------------- buildings great_roads mapserver_desc parcs personnes rivers small_roads (7 rows)
Le listing des tables peut facilement être obtenu en tapant simpelement '\dt' dans psql le moniteur interactif de PostgreSQL.
Note
Je pars ici du principe que toutes les tables sont contenues dans un même schéma et soient contenus sur un même espace logique de PostgreSQL. Mais si vous êtes sûr que toutes vos tables sont dans le même schéma, vous pouvez par exemple exploiter la requête
select tablename as nom_table from pg_tables where schemaname='public'
and tablename not in ('spatial_ref_sys','geometry_columns') order by tablename;PostgreSQL offre un concept fort appréciable concernant les SGDBR, celui des vues. Les vues permettent parfois de se simplifier la vie avec des requêtes parfois bien longue et que l'on ne pourrait pas toujours pouvoir se souvenir. Pour la requête concernant le listing des tables contenues dans une base de données - vu précédemment - on peut avoir recours aux vues en créant la la vue suivante
create view liste_table as select tablename as nom_table from pg_tables where (tablename not like 'pg_%') and (tablename not like 'spatial_ref_sys' ) and (tablename not like 'sql_%' ) and (tablename not like 'geom%' ) order by tablename;
On aura alors le listing attendu en faisant directement
select * from liste_table
Ces informations (srid, type, nom de la colonne géométrique) sont stockées dans la table geometrycolumns. La requête
select * from geometry_columns
nous renvoit les informations suivantes
f_table_catalog | f_table_schema | f_table_name | f_geometry_column | coord_dimension | srid | type
-----------------+----------------+--------------+-------------------+-----------------+------+------------
| public | personnes | the_geom | 2 | -1 | POINT
| public | buildings | the_geom | 2 | -1 | POLYGON
| public | small_roads | the_geom | 2 | -1 | LINESTRING
| public | great_roads | the_geom | 2 | -1 | LINESTRING
| public | parcs | the_geom | 2 | -1 | POLYGON
| public | rivers | the_geom | 2 | -1 | POLYGON
(6 rows)Les informations utiles sont
f_table_name qui fournit le nom de la table;
f_geometry_column qui donne le nom de la colonne géométrique;
srid fournit le srid - identifiant de système de projection-;
type qui fournit le type d'objet contenu dans la table.
Avertissement
Certains logiciels SIG - au sens large du terme - comme MapServer, JUMP ou QGIS exploitent cette table pour effectuer leurs requêtes attendues ou lister l'ensemble des tables exploitables. On comprend ainsi mieux son importance. Cette table ainsi que certains champs de cette table sont aussi spécifiés par l'O.G.C (Oprn GIS Consortium).
Comme il a été fait mention dans la sous-section précédente, la table geometry_columns contient toutes les métadonnées nécessaires à la gestion des tables géospatiales de notre base. Or il se peut qu'un jour nous ayons besoin d'une fonction qui puisse faire le différentiel entre les tables géospatiales de notre base avec les tables non géospatiales.
Il est alors possible d'utiliser la fonction suivante
create or replace function diff_geometry_columns(OUT j text) as $$
begin
select into j tablename as nom_table from pg_tables where
tablename not in ((select f_table_name from geometry_columns)
union
(select 'spatial_ref_sys') union (select 'geometry_columns'))
and pg_tables.schemaname='public';
end;
$$ language plpgsql;Ainsi l'appel de cette fonction par
select diff_geometry_columns();
j'obtiens
diff_geometry_columns ----------------------- mapserver_desc (1 ligne)
qui est bien la seule table non géospatiale - à part spatial_ref_sys - de ma base.
Note
Pour de plus amples informations sur PL/PGSQL, merci de consulter la documentation française de PostgreSQL à http://traduc.postgresqlfr.org/pgsql-8.1.1-fr/plpgsql.html
Avant la version 1.0.0 de PostGIS, les données étaient stockées sous forme WKT (Well-Known Text),c'est-à-dire un format lisible par le commun des mortels. PostGIS prenait aussi en compte les formats géométriques (sémantique, grammaire,tolopolgie...) des objets définis par l'OGC Open GIS Consortium. Pour des raison d'économie sur le disque de dur et pour un accès plus rapides, depuis la version 1.0.0, les formates acceptés par PostGIS sont les formats EWKB /EWKT. Depuis cette version, les formats supportés par PostGIS forment une extension des définitions des formats définis par l'OGC qui ne s'intéressaient qu'aux objets définis en 2D. On peut donc avoir des données 3d. Ainsi EWKB/EWKT sont une extension du WKB/WKT. WKB.WKT sont donc acceptés par PostGIS en tant que EWKB/EWKT en dimension 2D.
Note
Pour de plus amples informations, veuillez consulter la documentation de PostGIS.
L''accès direct aux objets géométriques en EWKB ne permet pas de lire leur contenus des données pour le commun des mortels. Je rappelle au passage qu'un objet spatial dans une base de données est défini par son type, l'ensemble ou les sous-ensembles de points qui le composent ainsi qu'au système de projection auquel il est attaché, et à la dimension (2d,3d ou 4d) auquel il appartient. PostgreSQL de son côté selon les processus internes de fonctionnement et les format d'entrée des objets spatiaux en mode ascii ou binaire choisi - ascii: HEXEWKB/EWT et binaire : EWKB - stockera respectievement en ascii: HEXEWKB et pour le binaire en EWKB.
Pour pouvoir respectivement lire les données aux formats EWKT - format lisible -, il faut avoir recours aux fonctions AsText() ou AsEWKT(), et Srid() pour connaître leur identiifant de système de projection. Par exemple pour la table personnes dont la colonne géométrique est the_geom, affichons ces diverses informations grâce à la requête suivante
SELECT AsText(the_geom), Srid(the_geom),the_geom FROM personnes
qui nous renvoit
astext | srid | the_geom ----------------------+------+-------------------------------------------- POINT(10 70) | -1 | 010100000000000000000024400000000000805140 POINT(30 30) | -1 | 01010000000000000000003E400000000000003E40 POINT(35 70) | -1 | 010100000000000000008041400000000000805140 POINT(35 60) | -1 | 010100000000000000008041400000000000004E40 POINT(30.54 118.28) | -1 | 01010000000AD7A3703D8A3E4052B81E85EB915D40 POINT(52.36 96.73) | -1 | 0101000000AE47E17A142E4A401F85EB51B82E5840 POINT(100.94 105.44) | -1 | 01010000005C8FC2F5283C59405C8FC2F5285C5A40 POINT(115.16 34.81) | -1 | 01010000000AD7A3703DCA5C4048E17A14AE674140 POINT(120.89 66.23) | -1 | 0101000000295C8FC2F5385E401F85EB51B88E5040 POINT(137.4 62.56) | -1 | 0101000000CDCCCCCCCC2C614048E17A14AE474F40 POINT(144.97 30.23) | -1 | 0101000000D7A3703D0A1F62407B14AE47E13A3E40 POINT(72.04 41.23) | -1 | 0101000000C3F5285C8F0252403D0AD7A3709D4440 POINT(52.32 6.84) | -1 | 0101000000295C8FC2F5284A405C8FC2F5285C1B40 (13 rows)
On voit bien ici le stockage réalisé en HEXEWKB des objets géométriques. En effet, si nous effectuons la requête suivante par exemple relatif au premier enregistrement pour le point POINT(35 70) ayant SRID=-1, on a comme attendu en utilisant la fonction GeomFromEWKT()
SELECT GeomFromEWKT('SRID=-1;POINT(35 70)');ou la requête équivalente
SELECT 'SRID=-1;POINT(35 70)'::geometry;
on obtient
geomfromewkt -------------------------------------------- 010100000000000000008041400000000000805140 (1 row)
PostgreSQL lit en entrée (mode ascii) du EWKT et restitue en stockage HEXEWKB (= EWKB sous forme hexadécimale)
Cet objet stocké en HEXEWKB a la forme suivante en EWKT, restitué grâce à la fonction AsEWKT()
select AsEWKT('010100000000000000008041400000000000805140');asewkt -------------- POINT(35 70) (1 ligne)
et en EWKB restitué grâce à AsEWKB()
select AsEWKB('010100000000000000008041400000000000805140');asewkb -------------------------------------------------------------------------- \001\001\000\000\000\000\000\000\000\000\200A@\000\000\000\000\000\200Q@ (1 ligne)
et comme srid, restitué grâce à la fonction Srid()
select Srid('010100000000000000008041400000000000805140'::geometry);srid ------ -1 (1 ligne)
En mode d'entrée, PostGIS accepte aussi le HEXEWKB directement et PostgreSQL le stockera tout simplement en HEXEWKB. Ainsi dans dans une table test dont la structure serait par exemple
CREATE TABLE test (...,
the_geom GEOMETRY);les deux insertions suivantes sont équivalentes
INSERT INTO test VALUES (...,
GeomFromEWKT('SRID=-1;POINT(35 70)')
);INSERT INTO test VALUES (...,
'010100000000000000008041400000000000805140'
);Ici il n'est pas besoin de précisé le type (::geometry) puisque la colonne the_geom est de type geometry.
La requête suivante
select data as batiment,
cast(area2d(the_geom) as decimal(15,2))||' m carre' as Aire,
cast(perimeter(the_geom) as decimal(15,2))||' m' as Perimetre
from buildingsnous renverra comme réponse
batiment | aire | perimetre -----------------------------+-----------------+----------- Collège Arthur Rimbaud | 1370.00 m carre | 187.61 m Résidence des Mousquetaires | 2915.00 m carre | 216.00 m Hotel des Impots | 1300.00 m carre | 190.00 m E.D.F | 476.43 m carre | 88.54 m Bibliothèque Victor Hugo | 900.00 m carre | 176.57 m Mairie | 936.00 m carre | 141.70 m Office du Tourisme | 205.55 m carre | 58.92 m (7 rows)
La requête suivante
select personnes.data as personnes_dans_batiment_2 from personnes,buildings
where within(personnes.the_geom,buildings.the_geom)
and buildings.data = 'Résidence des Mousquetaires';nous renverra comme réponse
personnes_dans_batiment_2 --------------------------- personne 1 personne 2 personne 3 personne 4 (4 rows)
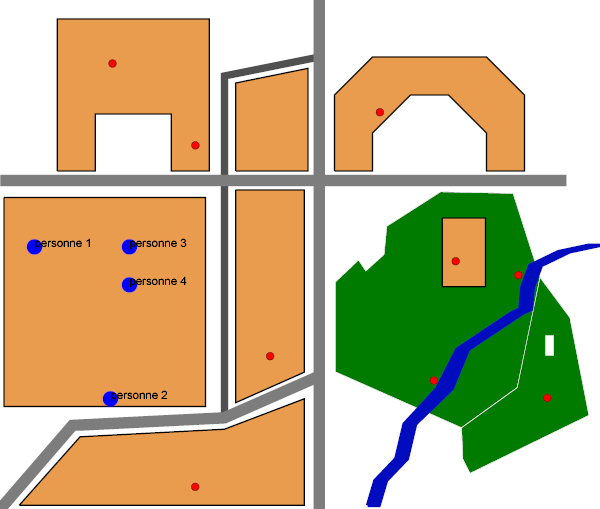
La requête suivante
select h.data as batiment_1,t.data as batiment_2, cast(Distance(t.the_geom,h.the_geom) as decimal(15,2))||' m' as distance_entre_batiment from buildings t, buildings h where h.data!=t.data;
nous renverra comme réponse
batiment_1 | batiment_2 | distance_entre_batiment -----------------------------+-----------------------------+------------------------- Résidence des Mousquetaires | Collège Arthur Rimbaud | 6.25 m Hotel des Impots | Collège Arthur Rimbaud | 64.97 m E.D.F | Collège Arthur Rimbaud | 60.00 m Bibliothèque Victor Hugo | Collège Arthur Rimbaud | 60.53 m Mairie | Collège Arthur Rimbaud | 5.47 m Office du Tourisme | Collège Arthur Rimbaud | 46.82 m Collège Arthur Rimbaud | Résidence des Mousquetaires | 6.25 m Hotel des Impots | Résidence des Mousquetaires | 7.00 m E.D.F | Résidence des Mousquetaires | 10.63 m Bibliothèque Victor Hugo | Résidence des Mousquetaires | 34.71 m Mairie | Résidence des Mousquetaires | 8.00 m Office du Tourisme | Résidence des Mousquetaires | 62.36 m Collège Arthur Rimbaud | Hotel des Impots | 64.97 m Résidence des Mousquetaires | Hotel des Impots | 7.00 m E.D.F | Hotel des Impots | 7.00 m Bibliothèque Victor Hugo | Hotel des Impots | 33.00 m Mairie | Hotel des Impots | 8.60 m Office du Tourisme | Hotel des Impots | 62.60 m Collège Arthur Rimbaud | E.D.F | 60.00 m Résidence des Mousquetaires | E.D.F | 10.63 m Hotel des Impots | E.D.F | 7.00 m Bibliothèque Victor Hugo | E.D.F | 7.00 m Mairie | E.D.F | 5.00 m Office du Tourisme | E.D.F | 37.47 m Collège Arthur Rimbaud | Bibliothèque Victor Hugo | 60.53 m Résidence des Mousquetaires | Bibliothèque Victor Hugo | 34.71 m Hotel des Impots | Bibliothèque Victor Hugo | 33.00 m E.D.F | Bibliothèque Victor Hugo | 7.00 m Mairie | Bibliothèque Victor Hugo | 9.43 m Office du Tourisme | Bibliothèque Victor Hugo | 12.40 m Collège Arthur Rimbaud | Mairie | 5.47 m Résidence des Mousquetaires | Mairie | 8.00 m Hotel des Impots | Mairie | 8.60 m E.D.F | Mairie | 5.00 m Bibliothèque Victor Hugo | Mairie | 9.43 m Office du Tourisme | Mairie | 36.36 m Collège Arthur Rimbaud | Office du Tourisme | 46.82 m Résidence des Mousquetaires | Office du Tourisme | 62.36 m Hotel des Impots | Office du Tourisme | 62.60 m E.D.F | Office du Tourisme | 37.47 m Bibliothèque Victor Hugo | Office du Tourisme | 12.40 m Mairie | Office du Tourisme | 36.36 m (42 rows)
Nous aurons ici recours à la fonction NumPoint() qui permet de déternimer le nombre de points qui compose un objet:
SELECT data,AsText(the_geom),NumPoints(the_geom) FROM great_roads
nous renvoit effectivement
data | astext | numpoints --------------------------+-----------------------------------+----------- Rue Paul Valéry | LINESTRING(1 1,20 23,60 25,85 36) | 4 Rue du Général de Gaulle | LINESTRING(1 87.5,150 87.5) | 2 Rue Aristide Briand | LINESTRING(85 1,85 135) | 2 (3 lignes)
StartPoint()et EndPoint() permettent facilement de répondre à cette question. D'où la requête suivante
SELECT data,AsText(the_geom),AsText(StartPoint(the_geom)),AsText(EndPoint(the_geom)) FROM great_roads where data like '%Valéry%'
data | astext | astext | astext -----------------+-----------------------------------+------------+-------------- Rue Paul Valéry | LINESTRING(1 1,20 23,60 25,85 36) | POINT(1 1) | POINT(85 36) (1 ligne)
On pourra utiliser les fonctions respectives AsText() pour avoir les points en WKT et Intersects() pour les tests d'intersection
SELECT s.data,g.data,AsText(Intersection(s.the_geom,g.the_geom)) FROM small_roads s, great_roads g WHERE Intersects(s.the_geom,g.the_geom)
renvoyant comme résultat
data | data | astext --------------+--------------------------+---------------- Rue Figaro | Rue du Général de Gaulle | POINT(60 87.5) Rue Figaro | Rue Aristide Briand | POINT(85 120) Rue Voltaire | Rue Paul Valéry | POINT(60 25) Rue Voltaire | Rue du Général de Gaulle | POINT(60 87.5) (4 lignes)
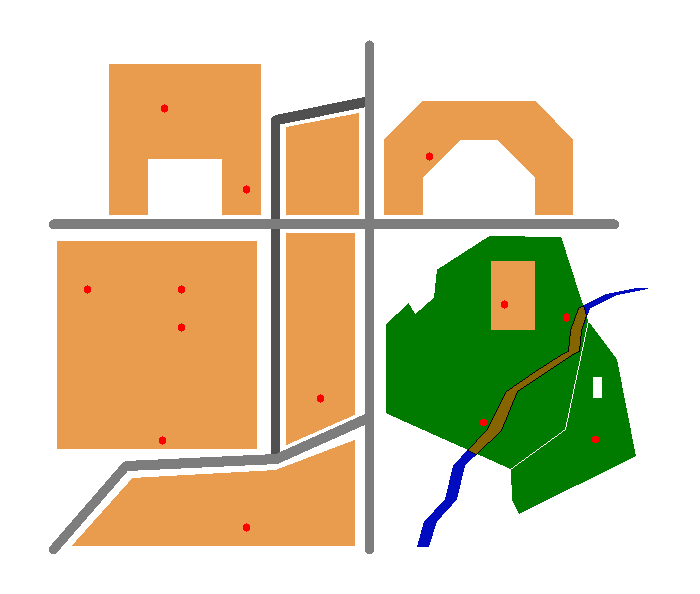
Plusieurs formulations sont possibles. Les requêtes suivantes
select q.data from personnes z,buildings q where z.data like 'personne 2' and Distance(z.the_geom,q.the_geom)= (select min(foo.valeur) from (select h.data as nom,distance(t.the_geom,h.the_geom) as valeur from personnes t, buildings h where t.data like 'personne 2') foo);
et celle-ci
SELECT data from( SELECT a.data,Distance(a.the_geom,b.the_geom) FROM buildings a,personnes b WHERE b.data='personne 2' ORDER BY distance ASC limit 1) as foo;
nous renvoient comme réponse
data ----------------------------- Résidence des Mousquetaires (1 ligne)
La requête suivante
select b.data from buildings b,
(select geomunion(the_geom) from personnes) gp
where
not intersects(gp.geomunion,b.the_geom);nous renverra comme réponse
data ------- E.D.F (1 row)
On utilisera pour cela la requête suivante
select p.data,b.data from personnes p, buildings b where intersects(p.the_geom,b.the_geom)
qui nous renverra
data | data -------------+----------------------------- personne 1 | Résidence des Mousquetaires personne 2 | Résidence des Mousquetaires personne 3 | Résidence des Mousquetaires personne 4 | Résidence des Mousquetaires personne 5 | Hotel des Impots personne 6 | Hotel des Impots personne 7 | Bibliothèque Victor Hugo personne 9 | Office du Tourisme personne 12 | Mairie personne 13 | Collège Arthur Rimbaud (10 lignes)
Cette requête est un peu plus poussée que la précédente car il se peut que ce nombre puisse valoir zéro. On peut par exemple utiliser la négation de la fonction de Contains() pour obtenir le nombre de personnes non présentes par bâtiment. Ce dernier nombre est alors soustrait du nombre total de personnes - nombre que l'on peut obtenir par le fonction Count() de PostgreSQL. Ce qui donnerait par exemple comme requête
SELECT (SELECT Count(*) FROM personnes)-Count(p.data) AS nombre_de_personnes,b.data as batiment FROM buildings b , personnes p WHERE NOT Contains(b.the_geom,p.the_geom) GROUP BY b.data ORDER BY b.data
nous renvoyant comme résultat
nombre_de_personnes | batiment
---------------------+-----------------------------
1 | Bibliothèque Victor Hugo
1 | Collège Arthur Rimbaud
0 | E.D.F
2 | Hotel des Impots
1 | Mairie
1 | Office du Tourisme
4 | Résidence des Mousquetaires
(7 lignes)La requête suivante
select cast(area2d(intersection(r.the_geom,p.the_geom)) as decimal(15,1)) ||' m carre' as Aire
from rivers r,
parcs p
where intersects(r.the_geom,p.the_geom);nous renverra comme réponse
aire ---------- 123.1 m carre (1 ligne)
L'affichage avec MapServer peut être obtenu en utilisant par exemple le LAYER suivant dans une mapfile
LAYER
CONNECTION "user=david dbname=madatabase host=localhost"
CONNECTIONTYPE POSTGIS
DATA "intersection FROM (select r.gid,intersection(r.the_geom,p.the_geom) FROM rivers r,parcs p
WHERE intersects(r.the_geom,p.the_geom)) foo USING UNIQUE gid USING SRID=-1"
NAME "requete"
TYPE POLYGON
STATUS DEFAULT
CLASS
STYLE
ANGLE 360
OUTLINECOLOR 0 0 0
COLOR 134 100 0
SIZE 5
SYMBOL 0
END
END
ENDAu niveau du visuel, on obtiendrait
La fonction Contains(A,B) permet de savoir si l'objet A contient l'objet B. De ce fait, la requête
select b.data from buildings b,parcs where Contains(parcs.the_geom,b.the_geom)
renvoit le résultat immédiat
data -------------------- Office du Tourisme (1 row)
Ici, nous allons utilisé un combinaison des fonctions Contains() que nous avons vu précédement et de aa fonction Buffer(A,r) où A est l'objet géométrique auquel on applique un buffer de rayon r . Pour rappel , Buffer(A,r) est l'objet - ensemble de points - dont la distance à l'objet A est inférieure où égale à r. La requête
select p.data from personnes p,rivers where contains(buffer(rivers.the_geom,5),p.the_geom);
nous renvoit alors comme réponse
data --------------- personne 8 personne 10 (2 rows)
Au niveau de MapServer pour un rendu visuel, il faut deux layers pour obtenir les résultats souhaités. Il en faut un pour afficher le buffer en question et l'autre pour afficher les résultats de la requête précédente.
Pour afficher le buffer, on pourra utiliser le layer suivant:
LAYER CONNECTION "user=david dbname=madatabase host=localhost" CONNECTIONTYPE POSTGIS DATA "buffer from (select gid,buffer(rivers.the_geom,5) from rivers) foo USING UNIQUE gid USING SRID=-1" NAME "requete_1" TYPE LINE STATUS DEFAULT CLASS STYLE OUTLINECOLOR 20 156 78 SIZE 10 SYMBOL 0 END END ENDPour afficher les données attendues, on pourra proposer:
LAYER CONNECTION "user=david dbname=madatabase host=localhost" CONNECTIONTYPE POSTGIS DATA "the_geom from (select * from personnes where contains(buffer(rivers.the_geom,5),personnes.the_geom)) foo USING UNIQUE gid USING SRID=-1" NAME "requete_2" LABELITEM "data" STATUS DEFAULT TYPE POINT CLASS LABEL COLOR 22 8 3 END STYLE COLOR 255 0 0 SIZE 8 SYMBOL "circle" END END END
Note
Il est aussi possible de n'avoir recours qu'à un seul layer pour afficher à la fois l'objet et les personnes attendues! Ce sera le cas lors de la prochaine section - sur les requêtes concernant une certaine table communes_avoisinantes -.
Le visuel sera alors le suivant
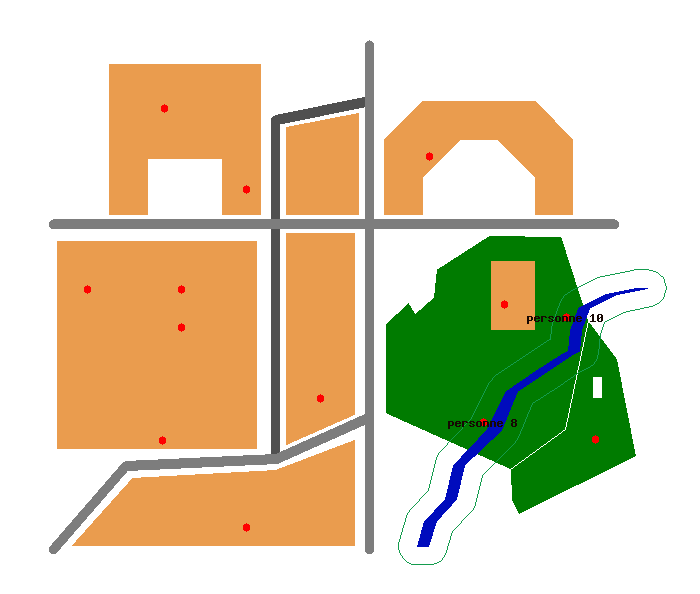
La requête suivante avec l'emploi de la fonction Nrings(geometry)
select data from parcs where nrings(the_geom)>1;
nous renvoit comme réponse
data ------------------- Parc Mangueret II (1 ligne)
En effet, cette fonction permet par exemple dans le cas d'un POLYGON ou d'un MULTIPOLYGON de déterminer le nombre de polygones faisant partie de la collection constituant l'objet:
select data,nrings(the_geom) from parcs;
data | nrings -------------------+-------- Parc Mangueret I | 1 Parc Mangueret II | 2 (2 lignes)
Pour répondre à cette question, il faut commencer par construire cette ligne en utilisant la fonction MakeLine(geometry,geometry) qui permet de relier entre eux deux points:
select astext(makeline(a.the_geom,b.the_geom)) from personnes a,personnes b where a.data='personne 5' and b.data='personne 13';
astext ------------------------------------- LINESTRING(30.54 118.28,52.32 6.84) (1 ligne)
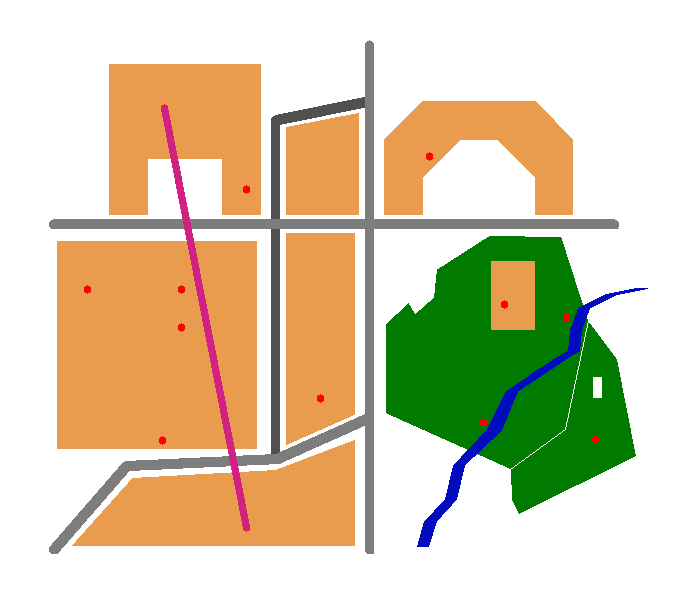
Il en résultera donc la requête suivante
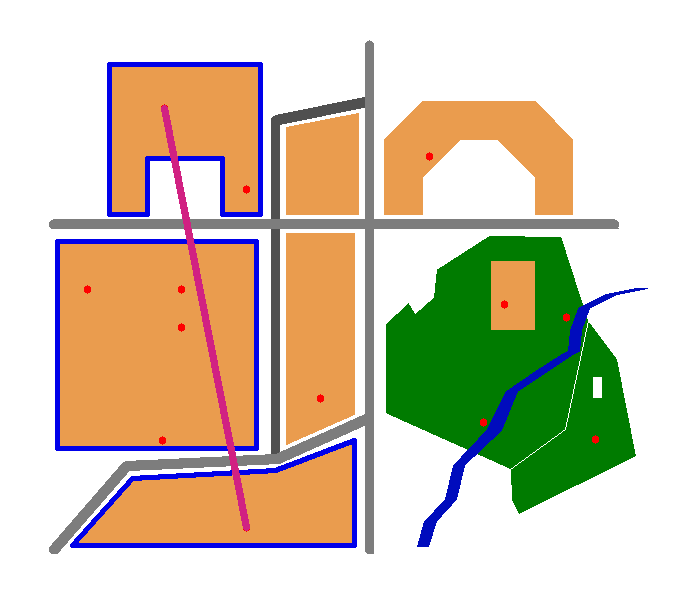
select build.data from buildings build where intersects( build.the_geom, (select makeline(a.the_geom,b.the_geom) from personnes a,personnes b where a.data='personne 5' and b.data='personne 13') );
data ----------------------------- Collège Arthur Rimbaud Résidence des Mousquetaires Hotel des Impots (3 lignes)
Le language PL/PGSQL sert tirer profit des procédures déclencheurs. Nous allons ici créer une table suivi_de_la_personne_7 qui enregistrera à tout moment demandé enregistrera les informations suivantes:
utilisateur correspondant au nom de l'utilsateur sous de PostgreSQL qui aura fait un update sur les données spatiales de la "personne 7";
date correspondant à l'heure à laquelle a eu lieu le déplacement;
suivi qui précisera si la personne est "dans" ou "proche" du batiment;
position qui donnera la position de la personne.
Nous aurons aussi besoin d'une fonction get_info_on_personne_7() écrite en PL/PGSQL appelé par le déclencheur qui nous renverra le bâtiment qui contient la personne 7 et dans le cas contraire le premier bâtiment qui lui est le plus proche.
/*
Rappel pour effacer un trigger
drop trigger suivi_7_date on personnes;
*/
/*
Table qui contiendra le suivi de la
personne 7 lors de ses déplacements
avec effacement éventuel avant création
*/
select drop_table_if_exists('suivi_de_la_personne_7',false);
create table suivi_de_la_personne_7(
utilisateur text,
date text,
suivi text,
position text
);
/*
Fonction appelée par le trigger
*/
create or replace function get_info_on_personne_7() returns trigger as $$
declare
j record;
begin
if (TG_OP = 'UPDATE') then
SELECT into j data,distance,astext(the_geom) from(
SELECT a.data,Distance(a.the_geom,b.the_geom),b.the_geom FROM buildings a,personnes b
WHERE b.data='personne 7'
ORDER BY distance ASC limit 1)
as foo;
if j.distance=0 then
insert into suivi_de_la_personne_7 values
(current_user,now(),'La personne 7 est dans le batiment '''||j.data::text||'''',j.astext::text);
RAISE NOTICE 'La personne 7 est dans le batiment ''%''',j.data;
else
insert into suivi_de_la_personne_7 values
(current_user,now(),'La personne 7 est proche du batiment '''||j.data::text||'''',j.astext::text);
RAISE NOTICE 'La personne 7 est proche du batiment ''%''',j.data;
end if;
end if;
return new;
end;
$$ language plpgsql;
/*
Création du trigger
*/
CREATE TRIGGER suivi_7_date AFTER UPDATE ON personnes
EXECUTE PROCEDURE get_info_on_personne_7();Procédons maintenant à quelques exemples de mise à jour des données spatiales de la personne 7:
madatabase=# update personnes set the_geom=geometryfromtext('POINT(100.94 105.44)',-1) where data='personne 7';
INFO: La personne 7 est dans le batiment 'Bibliothèque Victor Hugo'
UPDATE 1
madatabase=# update personnes set the_geom=geometryfromtext('POINT(100 70)',-1) where data='personne 7';
INFO: La personne 7 est proche du batiment 'Office du Tourisme'
UPDATE 1
madatabase=# update personnes set the_geom=geometryfromtext('POINT(120 66)',-1) where data='personne 7';
INFO: La personne 7 est dans le batiment 'Office du Tourisme'
UPDATE 1
madatabase=# update personnes set the_geom=geometryfromtext('POINT(0 0)',-1) where data='personne 7';
INFO: La personne 7 est proche du batiment 'Collège Arthur Rimbaud'
UPDATE 1
madatabase=# update personnes set the_geom=geometryfromtext('POINT(60 87.5)',-1) where data='personne 7';
INFO: La personne 7 est proche du batiment 'E.D.F'
UPDATE 1La simple requête suivante nous renvoit les divers informations obtenues lors du déplacement de la personne 7
testgis=# select * from suivi_de_la_personne_7 ; utilisateur | date | suivi | position -------------+-------------------------------+---------------------------------------------------------------+---------------------- postgres | 2006-01-12 12:05:01.989762+01 | La personne 7 est dans le batiment 'Bibliothèque Victor Hugo' | POINT(100.94 105.44) postgres | 2006-01-12 12:05:20.824226+01 | La personne 7 est proche du batiment 'Office du Tourisme' | POINT(100 70) postgres | 2006-01-12 12:05:41.106236+01 | La personne 7 est dans le batiment 'Office du Tourisme' | POINT(120 66) postgres | 2006-01-12 12:06:05.024382+01 | La personne 7 est proche du batiment 'Collège Arthur Rimbaud' | POINT(0 0) postgres | 2006-01-12 12:07:31.859971+01 | La personne 7 est proche du batiment 'E.D.F' | POINT(60 87.5) (6 lignes)
C'est le genre de petite application qui peut par exemple servir lors de suivi par une application-cliente (front-end) par le Web par exemple : interface cartographique en SVG ....
Nous allons exposer ici des exemples de requêtes sur des données SIG réelles. Les situations citées ici sont tirées de notre travail quotidien en tant qu'utiisateur de PostGIS et de MapServer.
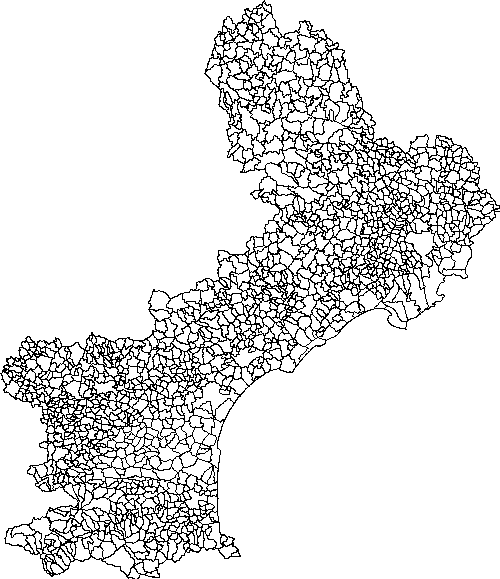
Ici les communes de cette région sont "fournies" au format ESRI Shapefiles dans le fichier communes_lr.shp. Ces données sont déjà identifiées dans le système de projection français Lambert II Carto Etendu. Sachant que dans ce cas précis, l'identifiant de projection (srid) vaut 27582, pour les importer dans notre base madatabase, il nous suffira de faire
shp2pgsql -s 27582 -DI communes_lr.shp communes_lr | psql madatabase
Reportez-vous à la documentation de shp2pgsql pour les options ici utilisées. Nous noterons au passage que la région du Languedoc-Roussillon est composée de 1545 communes soit 1545 enregistrements dans notre table.
Pour avoir le maximum d'information sur la structure de cette table, je ne saurais vous conseiller la documentation en ligne sur le site de PostGIS. Comme dit dans ce document , c'est la table spatial_ref_sys de PostGIS qui contient les informations relatives aux divers systèmes de projection - table requise selon les spécifications de l'O.G.C (Open GIS Consortium). Excecutez la requête suivante par exemple pour voir les divers types de projections relatives à la France.
select srid,auth_name,auth_srid,srtext from spatial_ref_sys where srtext like '%France%'
La ligne qui nous intéresse est celle pour laquelle srid vaut 27582. Son champs srtext vaut
PROJCS["NTF (Paris) / France II",GEOGCS["NTF (Paris)",asting",600000](...)AUTHORITY["EPSG","27582"]]
Dans le cas où les données ont déjà été importées et que lors de l'utilisation de shp2pgsql on a oublié d'utiliser l'option -s pour préciser le système de projection, PostGIS considère qu'il s'agit de données plannes du plan orthornormal. Il précise alors par défaut srid=-1. Ce qui peut-être contraignant par exemple si par la suite, nous soyons amenés à utiliser les fonctions Distance() ou Area2f() qui selon le système de projection peuvent donner des résultats faussées.
Pour préciser le système de projection, deux solutions possibles:
solution 1: recharger à nouveau les données en utilisant shp2pgsql avec les options respectives -s pour l'identifiant de projection et l'option -d qui permet d'effacer la table avant de recharger le fichier .shp d'origine. La commande sera donc
shp2pgsql -s 27582 -dDI communes_lr.shp communes_lr | psql madatabase
solution 2: garder les données déjà importées et modifier le srid à la volée. Pour cela, il faut avoir recours à la fonction UpdateGeometrySrid dont la synthaxe dans notre cas sera
SELECT UpdateGeometrySrid('communes_lr','the_geom',27582);
Dans les deux cas, les données sont mises à jours ainsi que les méta-données les concernant dans la table geometry_columns.
La table que nous avons créée contient pas moins de 1545 enregistrements. Normalement la création d'index spatiaux a lieu en ayant recours par exemple
CREATE INDEX [index_spatial_table] ON [table] USING gist([colonne_geometrique] gist_geometry_ops);
Or l'option -I de shp2pgsql permet de créer automatiquement un index spatial - suffixé _the_geom_gist - en pour chacun de ces enregistrements et évite d'avoir à se soucier de leur création par l'emploi de cette requête. Par exemple ici, cette option fait alors directement appel ici pour la table communes_lr à la requête d'indexation spatiale suivante
CREATE INDEX communes_lr_the_geom_gist ON communes_lr USING gist(the_geom gist_geometry_ops);
La création des index spatiaux peut s'avérer "gourmand". Pour que le planificateur de requêtes de PostgreSQL dispose des informations statistiques nécessaires et adéquates pour savoir quand avoir recours aux index spatiaux selon la fonction spatial demandée, il est nécessaire parfois de faire un VACUUM ANALYZE sur la base en cours
Nous reviendrons sur cet aspect plus tard. Pour résumer, nous dirons juste que à la suite d'une ou plusieurs importation(s) de données importante pour lesquelles il y a eu besoin de création d'index spatiaux Gist, il est recommandé d'utiliser la requête VACUUM ANALYZE
VACUUM ANALYZE
Note
Pour PostgreSQL 8.x.x, cette commande permet de collecter les informations statistiques de l'emploi des index spatiaux
Par définiton, je rappelle que l'étendue géographique d'un objet spatial dans une base de données est la plus petit fenêtre (=rectangle) qui le contienne. Ce dernier est défini par le quadruplet (Xmin,Ymin,Xmax,Ymax) . (Xmin,Ymin) (respectivement (Xmax,Ymax)) est le sommet inférieur gauche (respectivement le sommet supérieur droit) du rectangle dans tout système de projection orienté de gauche à droite horizontalement et de bas en haut vertivalement.
Pour connâitre ce quadruplet, la requête suivante
SELECT Xmin(foo.extent),
Ymin(foo.extent),
Xmax(foo.extent),
Ymax(foo.extent)
FROM
(SELECT Extent(the_geom) FROM communes_lr) AS foonous renvoit comme résultat
xmin | ymin | xmax | ymax --------+-------------+--------+------------- 547293 | 1703209.875 | 801423 | 1997767.125 (1 row)
Ce dernier implique donc que tous les objets de la colonne géométrique the_geom sont contenus dans le quadruplet ci-dessus obtenu.
Note
Connaître l'étendue géographique peut s'avérer utile, notamment avec Mapserver dont les fichiers mapfiles possèdent un paramètre EXTENT qui correspond à l'étendue géogpraphique. Ici il s'agira de fournir ce quadruplet.
Cette section suppose que l'emploi de MapServer vous soit familier. Je ne passerais pas ici en revue les divers fonctionnements de MapServer. Je profite de l'occasion juste pour détailler de quoi est composer la plus petite couche - LAYER au sens de MapServer - pour PostGIS. Je pars ici du principe que vous avez Apache, Php et PhpMapScript d'installés sur votre machine.
Note
Pour disposer de tous ces outils, le mieux est de recourir au paquet MS4W (MapServer For Windows) disponible sur le site http://www.maptools.org
Pour construire mon image sur les communes du Languedoc-Roussillon, le premier paramètre à fournir est bien l'EXTENT. Or selon une des dimensions de l'image que je me fixe (longueur ou hauteur), il me faut aussi savoir qu'elle sera la valeur de l'autre dimensions.
Il suffit pour cela d'effectuer une simple règle de trois que me donne la requête suivante inspirée de la requête de la section précédente:
SELECT
500*(abs(Ymax(foo.extent)-Ymin(foo.extent))/abs(Xmax(foo.extent)-Xmin(foo.extent)))
AS hauteur
FROM (SELECT Extent(the_geom) FROM communes_lr) AS fooqui me renvoie
hauteur ------------------ 579.540491087239 (1 ligne)
Pour afficher ma table communes_lr, ayant l'étendue géographique et la hauteur de l'image, je peux par exemple avoir comme mapfile appelée communes_lr.map
MAP
EXTENT 547293 1703209.875 801423 1997767.125
IMAGECOLOR 255 255 255
IMAGETYPE png
SIZE 500 579.540491087239
WEB
IMAGEPATH "c:/wamp/www/tutorial/tmp/"
IMAGEURL "/tutorial/tmp/"
END
#
# Couche des communes
#
LAYER
NAME "communes_lr"
CONNECTION "user=david dbname=madatabase host=localhost"
CONNECTIONTYPE POSTGIS
DATA "the_geom from communes_lr"
STATUS DEFAULT
TYPE POLYGON
CLASS
STYLE
COLOR 255 255 255
OUTLINECOLOR 0 0 0
END
END
END
ENDavec comme paramètres au niveau générale
EXTENT qui prend comme paramètres le quadruplet Xmin Ymin Xmax Ymax;
IMAGECOLOR prend comme valeur un RGB (Red Green Blue) pour définir le fond de couleur. Ici 255 255 255 pour avoir du blanc;
IMAGETYPE png pour préciser que l'image produite sera au format png. cela suppose que MapServer est été compilé avec l'option --with-png pr défaut comme OUTPUTFORMAT;
SIZE qui prend comme paramètres Longueur Hauteur
au niveau du WEB:
IMAGEPATH pour préciser le chemin d'accès absolue sur le disque où seront générées les images produites;
IMAGEURL url relative à la valeur donnée par IMAGEPATH
au niveau de la couche - LAYER - pour la table communes_lr
CONNECTION suivi des paramètres de connection à PostgreSQL;
CONNECTIONTYPE POSTGIS pour préciser qu'il s'agit d'une connection à une base de données PostGIS;
DATA dont la pseudo-valeur doit être "colonne_geometrique from table". On met donc ici "the_geom from communes_lr" sans le mot-clé SELECT.
TYPE qui précise la nature géométrique des objets à afficher. TYPE peut prendre la valuer POINT, LINE ou POLYGON.
le reste au niveau du CLASS/STYLE concerne l'habillage pour l'affichage des objets. Ici un contour noir (OUTLINECOLOR 0 0 0 et un intérieur blanc (COLOR 255 255 255)
Au niveau de php grâce à - l'extension phpmapscript si vous l'avez installé - pour générer l'image on peut utiliser le script suivant -
<html>
<body>
<?php
$sw_MapFile = "./mapfiles/communes_lr.map";
$map = ms_newMapObj( $sw_MapFile );
$image = $map->draw();
$image_url = $image->saveWebImage(MS_PNG,1,1,0);
echo "<IMG
BORDER=0
SRC='".$image_url."'
width='".$map->width."' height='".$map->height."'/>
<BR>";
?>
</body>
</html>On obtiendra ainsi le visuel suivant
Dans le cas de certaines fonctions de PostGIS, parmi lesquelles nous pouvons citer Distance(); WithIn(), Intersects() [...]. ,il est parfois nécessaire selon la résultat escompté de les coupler à && := opérateur de chevauchement des étendues géographiques.
En effet, celui-ci sait tirer profit des index spatiaux - en interne de son implémentation, nous dirons qu'il les exploite-. Comme son nom l'indique, il teste si les étendues géographiques de deux objets géométriques A et B sechevauchent.
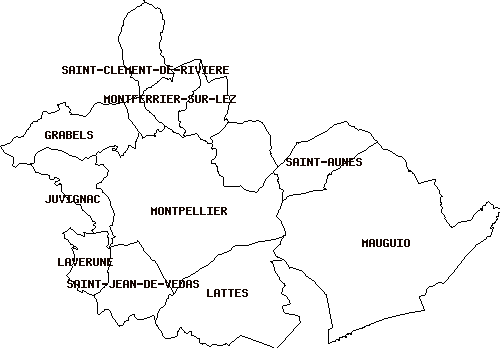
A titre d'exemple, pour avoir la liste des communes qui avoisines Montpellier, il s'agit simplement des communes dont la distance à Montpellier est nulle, ce qui sous-entend donc que leurs étendues géographiques se chevauchent- nous aurons recours à l'utilisation de l'opérateur && pour accélérer le temps nécessaire à la requête. D'où la requête suivante
SELECT b.nom FROM communes_lr a, communes_lr b
WHERE
a.nom LIKE 'MONTPELLIER'
AND
b.nom NOT LIKE 'MONTPELLIER'
AND
Distance(a.the_geom,b.the_geom)=0
AND
a.the_geom && b.the_geom
ORDER BY b.nomqui nous renvoit
nom -------------------------- CASTELNAU-LE-LEZ CLAPIERS GRABELS JUVIGNAC LATTES LAVERUNE MAUGUIO MONTFERRIER-SUR-LEZ SAINT-AUNES SAINT-CLEMENT-DE-RIVIERE SAINT-JEAN-DE-VEDAS (11 rows)
Sans l'utilisation ici de a.the_geom && b.the_geom, le temps demandé par la requête s'avère long - j'en témoigne pour 1544 enregistrements à tester! -.
Note
Il est également possible d'utiliser une fonction plus performante que la focntion Distance avec la condition Distance(A,B)=0 . On aurait pû avoir recours à la fonction Touches(A,B) qui permet de savoir si A et B se touchent puisqu'ici nous savons que les communes ne se "touchent" que par leur frontière
Pour mettre en évidence le temps mis par PostgreSQL pour exécuter la requête de la section précédente avec et sans la condition a.the_geom && b.the_geom, le mieux serait donc de reprendre la requête en la combinant aux mot-clés EXPLAIN ANALYZE
Note
Je n'exposerais pas ici les explications faisant appel au planificateur de tâches et à l'optimisateur de requêtes de PostgreSQL. Le mieux à mon sens est de se référer à la documentation officielle de PostgreSQL.
La requête suivante
EXPLAIN ANALYZE
SELECT b.nom FROM communes_lr a, communes_lr b
WHERE
a.nom LIKE 'MONTPELLIER'
AND
b.nom NOT LIKE 'MONTPELLIER'
AND
Distance(a.the_geom,b.the_geom)=0
AND
a.the_geom && b.the_geom
ORDER BY b.nomnous renvoit comme réponse
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=131.34..131.35 rows=1 width=32) (actual time=932.000..932.000 rows=11 loops=1)
Sort Key: b.nom
-> Nested Loop (cost=0.00..131.33 rows=1 width=32) (actual time=230.000..921.000 rows=11 loops=1)
Join Filter: (distance("outer".the_geom, "inner".the_geom) = 0::double precision)
-> Seq Scan on communes_lr a (cost=0.00..83.31 rows=8 width=32) (actual time=10.000..10.000 rows=1 loops=1)
Filter: ((nom)::text ~~ 'MONTPELLIER'::text)
-> Index Scan using communes_lr_the_geom_gist on communes_lr b (cost=0.00..5.98 rows=1 width=64) (actual time=10.000..20.000 rows=17 loops=1)
Index Cond: ("outer".the_geom && b.the_geom)
Filter: ((nom)::text !~~ 'MONTPELLIER'::text)
Total runtime: 932.000 ms
(10 lignes)soit un temps de 0.9 secondes (cf Total runtime: 932.000 ms). On voit bien d'après les résultats que l'index spatiaux est utilisé (cf "Index Scan using communes_lr_the_geom_gist on communes_lr", index créé automatiquement lors de l'importation des données par l'option -I de shp2pgsql.)
La même requête mais sans la contrainte
EXPLAIN ANALYZE
SELECT b.nom FROM communes_lr a, communes_lr b
WHERE
a.nom LIKE 'MONTPELLIER'
AND
b.nom NOT LIKE 'MONTPELLIER'
AND
Distance(a.the_geom,b.the_geom)=0
ORDER BY b.nomrenvoit comme résultat
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Sort (cost=476.08..476.23 rows=62 width=32) (actual time=152159.000..152159.000 rows=11 loops=1)
Sort Key: b.nom
-> Nested Loop (cost=83.32..474.23 rows=62 width=32) (actual time=74577.000..152159.000 rows=11 loops=1)
Join Filter: (distance("inner".the_geom, "outer".the_geom) = 0::double precision)
-> Seq Scan on communes_lr b (cost=0.00..83.31 rows=1538 width=64) (actual time=0.000..50.000 rows=1544 loops=1)
Filter: ((nom)::text !~~ 'MONTPELLIER'::text)
-> Materialize (cost=83.32..83.40 rows=8 width=32) (actual time=0.006..0.013 rows=1 loops=1544)
-> Seq Scan on communes_lr a (cost=0.00..83.31 rows=8 width=32) (actual time=10.000..20.000 rows=1 loops=1)
Filter: ((nom)::text ~~ 'MONTPELLIER'::text)
Total runtime: 152189.000 ms
(10 lignes)ce qui s'apparente à un temps d'exécution d'environ 2 minutes 30 (cf. Total runtime: 152189.000 ms). Ce qui est énorme!!! Ici, comme attendu il n'est pas fait usage des index spatiaux - par rapport à l'opérateur de chevauchement && -.
Ici par rapport au résultat avec l'opérateur && de la section précédente, la ligne pour la table 'communes_lr b'
-> Seq Scan on communes_lr b [... ] (actual time=0.000..50.000 rows=1544 loops=1) [...]
implique que 1544 enregistrements (cf rows=1544) de la table communes_lr ont été testés. Or si on enlève l'enregistrement qui correspond à celui de MONTPELLIER ('condition de la requête a.nom LIKE 'MONTPELLIER'), cela fait 1545 enregistrements. Soit le total d'enregistrement contenu dans la table communes_lr. Ce qui suppose donc que tous les enregistrements de la table ont été testés! Ce qui est justement l'opposé du bénéfice des index en bases de données.
En effet, avec l'opérateur && le coût de la table 'communes_lr b' s'élève à 17 enregistrements qui sont testés!
-> Index Scan using communes_lr_the_geom_gist on communes_lr b [...] (actual time=10.000..20.000 rows=17 loops=1)
Résultat qui exploite les index spatiaux!
On pourrait se contenter d'entrée de dire que la réponse directe serait de faire à la volée
CREATE TABLE communes_avoisinantes AS
(
SELECT b.* FROM communes_lr a, communes_lr b
WHERE
a.nom LIKE 'MONTPELLIER'
AND
Distance(a.the_geom,b.the_geom)=0
AND
a.the_geom && b.the_geom
ORDER BY b.nom
)Le premier souci qui se pose est que l'on n'a pas ici les méta-données concernant la nouvelle table référencées dans la table geometry_columns. On peut s'arrêter là si on n'a pas besoin d'utiliser cette table pour un affichage ultérieure avec MapServer.
Or dans le cas contraire d'un affichage avec MapServer, il est nécessaire que les métadonnées concernant la nouvelle table soient fournies dans la tables geometry_columns. En effet, quand il s'agit de données PostGIS à afficher, MapServer se sert de la fonction find_srid() qui elle s'appuie sur la table geometry_columns pour connaître l'identifiant de projection à utiliser.
Le mieux est alors d'avoir recours à quelques requêtes basique.s. On pourra essayer les requêtes successives décrites ici pour répondre à tous ces impératifs:
/*
On commence par effacer la table communes_avoisinantes
si elle exite déjà.
Ceci au cas où nous serions amenés à recharger ce fichier.
On peut aussi utiliser la commande: DROP TABLE communes_avoisinantes
*/
SELECT drop_table_if_exists('communes_avoisinantes',false);
/*
On crée une table vide communes_avoisinantes
pour cela, il suffit de demander de retourner la table communes_lr avec 0 lignes.
On obtient ainsi la même structure que la table communes_lr
*/
CREATE TABLE communes_avoisinantes AS
SELECT * FROM communes_lr LIMIT 0;
/*
On efface la colonne geometrique 'the_geom' dans la table communes_avoisinantes
car pour l'instant celle-ci n'est par référencée comme il faut
dans la table geometry_columns
*/
ALTER TABLE communes_avoisinantes DROP COLUMN the_geom;
/*
On ajoute la colonne 'the_geom' proprement en utilisant AddGeometryColumn()
Ici, on joue le jeu que l'on ne connaît de la table
communes_lr que son nom. On ignore donc le type
géométrique, son srid...Toutes ces informations sont stockées
dans la table geometry_columns.
*/
SELECT AddGeometryColumn('communes_avoisinantes'::varchar,
foo.f_geometry_column::varchar,
foo.srid::integer,
foo.type::varchar,
foo.coord_dimension::integer
)
FROM (
SELECT * FROM geometry_columns WHERE
f_table_name LIKE 'communes_lr'
) AS foo;
/*
On insère maintenant les données attendues dans la table
*/
INSERT INTO communes_avoisinantes
(
SELECT b.* FROM communes_lr a, communes_lr b
WHERE
a.nom LIKE 'MONTPELLIER'
AND
Distance(a.the_geom,b.the_geom)=0
AND
a.the_geom && b.the_geom
ORDER BY b.nom
);Note
A partir de l'étude réalisée pour la table communes_lr, il est alors aisé de pouvoir visualiser le contenu de cette table dans MapServer.
Nous ici pour cela utiliser la table communes_avoisinantes. Toutes ces résultats peuvent être obtenue grâce à la requête suivante:
SELECT fooo.nom,
AsText(Intersection(foo.the_geom,fooo.the_geom)),
AsSVG(Intersection(foo.the_geom,fooo.the_geom))
FROM (
SELECT the_geom FROM communes_avoisinantes
WHERE nom LIKE 'MONTPELLIER'
) AS foo
,
(
SELECT nom,the_geom FROM communes_avoisinantes
WHERE nom LIKE 'JUVIGNAC' OR nom LIKE 'LATTES'
) AS fooo ;ou sinon la requête suivante possible
SELECT b.nom,
AsText(Intersection(a.the_geom,b.the_geom)),
AsSVG(Intersection(a.the_geom,b.the_geom))
FROM communes_avoisinantes a,communes_avoisinantes b
WHERE a.nom='MONTPELLIER'
AND (b.nom='LATTES' OR b.nom='JUVIGNAC');Je n'afficherais pas ici les résultats obtenus car ces derniers prennent trop de place en affichage. Je me contenterais de les résumés ainsi
nom | intersection | assvg ----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ JUVIGNAC | MULTILINESTRING((719652.990195505 1844379.97900231,[...]718841.967178608 1849682.04627155)) | M 719652.9901955052 -1844379.9790023109 [...] 718841.96717860829 -1849682.0462715544 LATTES | MULTILINESTRING((729577.052318637 1845119.97019685,[...],723311.014479515 1841729.00265142))| M 729577.05231863656 -1845119.9701968494[...] 723311.01447951456 -1841729.0026514169 (2 lignes)
Au niveau de l'affichage on obtient
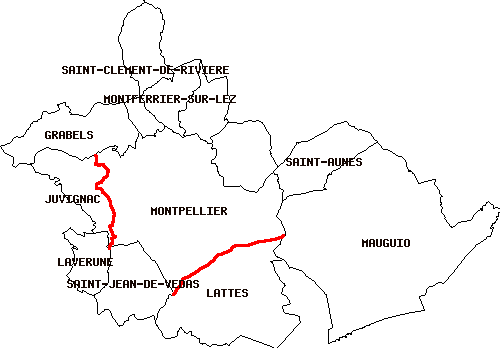
Il suiif par exemple d'utiliser la fonction Min() et Area2d() pour avoir comme requête:
SELECT nom FROM communes_avoisinantes
WHERE Area2d(the_geom) = (SELECT Min(Area2d(the_geom)) FROM communes_avoisinantes)nous renvoyant comme réponse
nom ---------- LAVERUNE (1 row)
Le visuel sera alors le suivant
Je fournis ci après la mapfile qui permet d'afficher la table communes_avoisinantes, ainsi que les deux requêtes précédemment poser. Il est à noter surtout la formulation des requêtes - paramètre DATA - pour pouvoir afficher les objets attendues.
MAP
EXTENT 713413.9375 1838659.875 741999.0625 1858572.125
FONTSET "c:\wamp\www\tutorial\etc\fonts.txt"
SYMBOLSET "c:\wamp\www\tutorial\etc\symbols.sym"
IMAGECOLOR 255 255 255
IMAGETYPE png
SIZE 500 348.297409929115
# STATUS ON
WEB
IMAGEPATH "c:/wamp/www/tutorial/tmp/"
IMAGEURL "/tutorial/tmp/"
END
#===============================================================================
# La table communes_avoisinantes
#===============================================================================
LAYER
NAME "communes_avoisinantes"
CONNECTION "user=david dbname=madatabase host=localhost"
CONNECTIONTYPE POSTGIS
DATA "the_geom from communes_avoisinantes"
STATUS DEFAULT
TYPE POLYGON
LABELITEM "nom"
CLASS
LABEL
SIZE MEDIUM
TYPE BITMAP
BUFFER 0
COLOR 22 8 3
FORCE FALSE
MINDISTANCE -1
MINFEATURESIZE -1
OFFSET 0 0
PARTIALS TRUE
POSITION CC
END
STYLE
COLOR 255 255 255
OUTLINECOLOR 0 0 0
END
END
END
#===============================================================================
# Requête 1: Intersection entre Montpellier et les communes de LATTES et JUVIGNAC
#===============================================================================
LAYER
NAME "requete_1"
CONNECTION "user=david dbname=madatabase host=localhost"
CONNECTIONTYPE POSTGIS
DATA "intersection from
(SELECT
intersection(foo.the_geom,fooo.the_geom),fooo.nom,fooo.gid
FROM (
SELECT * FROM communes_avoisinantes
WHERE nom LIKE 'MONTPELLIER'
) AS foo
,
(
SELECT * FROM communes_avoisinantes
WHERE nom LIKE 'JUVIGNAC' OR nom LIKE 'LATTES'
) AS fooo
)AS uo USING UNIQUE gid USING SRID=27582"
STATUS OFF
TYPE LINE
LABELITEM "nom"
CLASS
STYLE
OUTLINECOLOR 255 0 0
SIZE 3
SYMBOL "circle"
END
END
END
#===============================================================================
# Requête 2: La plus petite commune autour de Montpellier
#===============================================================================
LAYER
NAME "requete_2"
CONNECTION "user=david dbname=madatabase host=localhost"
CONNECTIONTYPE POSTGIS
DATA "the_geom from
(SELECT the_geom,nom,gid FROM communes_avoisinantes
WHERE Area2d(the_geom) = (SELECT Min(Area2d(the_geom)) FROM
communes_avoisinantes))AS uo USING UNIQUE gid USING SRID=27582"
STATUS DEFAULT
TYPE LINE
LABELITEM "nom"
CLASS
STYLE
OUTLINECOLOR 255 0 0
SIZE 3
SYMBOL "circle"
END
END
END
ENDLa région du Languedoc-Roussillon est composée de 5 départements dont voici la liste
Aude 11;
Hérault 34;
Gard 30;
Lozère 48;
Pyrénées Orientales 66.
Normalement lorsqu'on dispose des limites communales d'une région on doit aussi pouvoir disposer des limites départementales de cette dernière. Nous partirons ici du principe que nous ne disposons que de la table communes_lr. C'est à partir de cette table que nous allons créer nos limites départementales. Nous allons mettre les contours départementaux dans une table departements_lr ayant la structure suivante
CREATE TABLE departements_lr(id serial,nom text,numero integer);
où nom désignera le nom du département et numero son numéro. Comme pour l'instant, je ne sais pas quel est la la nature des objets géométrique, je fais juste
SELECT AddGeometryColumn('departements_lr_tmp','the_geom',27582,'GEOMETRY',2);Je remplis maintenant la table pour tous les départements
INSERT INTO departements_lr ( select 1 as id,'Herault'::text as nom,34 as numero,geomunion(the_geom) as the_geom from communes_lr where insee like '34%' ); INSERT INTO departements_lr ( select 2 as id,'Gard'::text as nom,30 as numero,geomunion(the_geom) as the_geom from communes_lr where insee like '30%' ); INSERT INTO departements_lr ( select 3 as id,'Lozère'::text as nom,48 as numero,geomunion(the_geom) as the_geom from communes_lr where insee like '48%' ); INSERT INTO departements_lr ( select 4 as id,'Aude'::text as nom,11 as numero,geomunion(the_geom) as the_geom from communes_lr where insee like '11%' ); INSERT INTO departements_lr ( select 5 as id,'Pyrénées Orientales'::text as nom,66 as numero,geomunion(the_geom) as the_geom from communes_lr where insee like '66%' );
Je ne cache pas qu'ici le peuplement de la table m'a pris 7 à 8 minutes quand même! Compréhensible dans le sens où faire/calculer la réunion géométrique de plusieurs objets géométriques demande du temps.
Pour savoir quel est le type de données géométriques adéquates, il faut utiliser la commande
select nom,geometrytype(the_geom) from departements_lr
qui me renvoit
nom | geometrytype ---------------------+-------------- Herault | MULTIPOLYGON Gard | POLYGON Lozère | POLYGON Aude | POLYGON Pyrénées Orientales | POLYGON (5 lignes)
Je réordonne les tables geometry_columns en mettant le type de departements_lr à MULTIPOLYGON et je convertis tous les departements en MULTIPOLYGON grâce à la fonction Multi() de PostGIS.
update geometry_columns set type='MULTIPOLYGON' where f_table_name='departements_lr'; update departements_lr set the_geom=(multi(the_geom::text));
il faut ensuite créer l'index spatial sur la table departements_lr et faire un vacuum analyze sur la base.
create index departements_lr_the_geom_gist on departements_lr using gist(the_geom gist_geometry_ops); vacuum analyze;
Au niveau de la mapfile, il faudrait ajouter le layer suivant
#==========================================================
# Couche des départements
#==========================================================
LAYER
NAME "departements_lr"
CONNECTION "user=david dbname=madatabase host=localhost"
CONNECTIONTYPE POSTGIS
DATA "the_geom from departements_lr"
STATUS DEFAULT
TYPE POLYGON
LABELITEM "nom"
CLASS
LABEL
SIZE MEDIUM
TYPE BITMAP
BUFFER 0
COLOR 22 8 3
FORCE FALSE
MINDISTANCE -1
MINFEATURESIZE -1
OFFSET 0 0
PARTIALS TRUE
POSITION CC
END
STYLE
OUTLINECOLOR 255 0 0
SIZE 3
SYMBOL "circle"
END
END
ENDAI niveau de l'afffichage, on obtient alors
Comme je sais ici que les communes des départements du Gard et de l'Aude commencent respectivement par 30 et 11, je vais pour cela utiliser la fonction Touches de PostGIS.
Au niveau de la mapfile, je ferais simplement
#==========================================================
# requete
#==========================================================
LAYER
NAME "requete"
CONNECTION "user=david dbname=madatabase host=localhost"
CONNECTIONTYPE POSTGIS
DATA "the_geom from (
select c.* from departements_lr d,communes_lr c
where touches(d.the_geom,c.the_geom)
and d.the_geom && c.the_geom
and d.nom='Herault'
and (c.insee like '11%' or c.insee like '30%')
) as foo USING UNIQUE gid USING SRID=27582"
STATUS DEFAULT
TYPE POLYGON
CLASS
LABEL
SIZE MEDIUM
TYPE BITMAP
BUFFER 0
COLOR 22 8 3
FORCE FALSE
MINDISTANCE -1
MINFEATURESIZE -1
OFFSET 0 0
PARTIALS TRUE
POSITION CC
END
STYLE
OUTLINECOLOR 0 0 255
SIZE 2
SYMBOL "circle"
END
END
END
Au niveau de l'affichage avec MapServer, j'obtiens
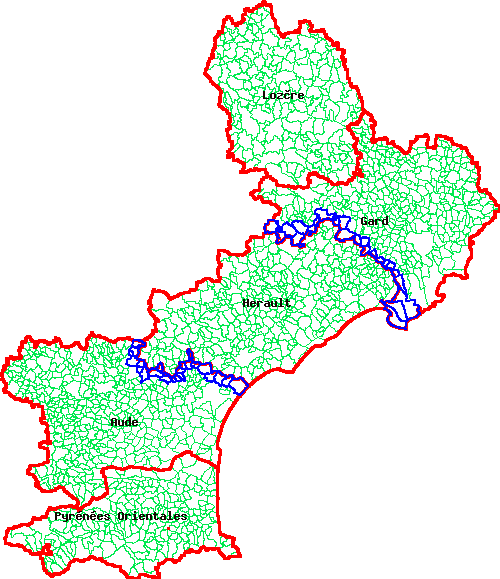
[1] Ce script est aussi disponible à l'adresse http://www.postgis.fr/download/win32/madatabase.zip
[2] voir pour cela le chapitre 'Paramétrer PostgreSQL'