Table des matières
- 6.1. Cas pratique I: Etude détaillée, manipulation de données, cas pratique avec MapServer
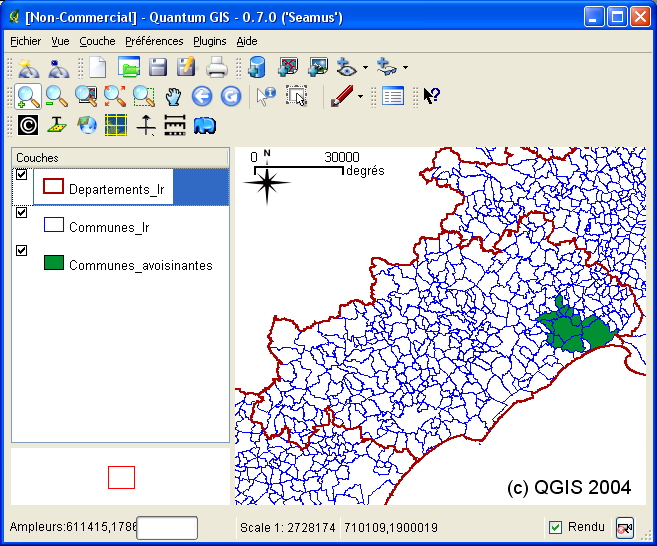
- 6.1.1. Importation des communes du Languedoc-Roussillon
- 6.1.2. Afficher les informations relatives au Lambert II Etendu depuis la table spatial_ref_sys - get_proj4_from_srid() -
- 6.1.3. Question: Comment faire pour effacer la colonne géométrique sans effacer les données attributaires ? - DropGeometryColumn() -
- 6.1.4. Question: Comment faire pour effacer une table géométrique, avant une réimportation si les méta-données à utiliser vont changer?
- 6.1.5. Question: Comment faire si on a oublié de préciser l'identifiant de système de projection? - UpdateGeometrySrid() -
- 6.1.6. Question: Si on s'est trompé dans le système de projection, comment faire pour reprojetter dans un autre système de manière définitive ? - Transform() -
- 6.1.7. Création d'index spatiaux Gist, Vacuum de la base
- 6.1.8. Question: Qu'elle est l'étendue géographique/emprise de la table communes_lr? - Extent() -
- 6.1.9. Visualisation des données avec MapServer
- 6.1.10. Question: Quelles sont les comunes avoisinantes de Montpellier?, Utilité des index spatiaux - Distance(), && -
- 6.1.11. Utilité des index spatiaux - temps demandé pour exécuter la requête
- 6.1.12. Créer une table communes_avoisinantes correspondant aux communes avoisinantes de MONTPELLIER, extraite et conforme à la structure de la table communes_lr, exploitable par MapServer.
- 6.1.13. Requête 1: Qu'elle est l'intersection entre MONTPELLIER et les communes de LATTES et de JUVIGNAC?- Intersection()- Que vaut cette géométrie en SVG? - AsSVG(),
- 6.1.14. Requête 2: Qu'elle est la commune ayant la plus petite aire?
- 6.1.15. Mapfile générale pour la table communes_avoisinantes et les deux requêtes précédentes
- 6.1.16. Exercice: Obtenir une table departements_lr qui contient les contours départmentaux du Languedoc-Roussillon à partir de la table communes_lr
- 6.1.17. Exercice: Trouver les communes du Gard et de l'Aude qui sont limitrophes à l'Hérault et les afficher grâce à MapServer.
- 6.1.18. QGIS: Affichage des tables précédentes
- 6.1.19. Exemple de projet sous GNU/Linux avec MapServer/PostgreSQL/PostGIS: savoir si à une échelle donnée, quel sera le meilleur format d'impression de A4 à A0 pour savoir si un polygone ne débordera du cadre de la carte
- 6.2. Cas pratique II: Réunifier des tronçons d'un réseau hydrologique d'un département
Après avoir passé en revue quelques unes des fonctionnalités de PostGIS, nous allons ici dans ce chapitre passer en revue quelques études de cas avec des données réelles.
Nous allons exposer ici des exemples de requêtes sur des données SIG réelles. Les situations citées ici sont tirées de notre travail quotidien en tant qu'utiisateur de PostGIS et de MapServer.
Ici les communes de cette région sont "fournies" au format ESRI Shapefiles dans le fichier communes_lr.shp. Ces données sont déjà identifiées dans le système de projection français Lambert II Carto Etendu. Sachant que dans ce cas précis, l'identifiant de projection (srid) vaut 27582, pour les importer dans notre base madatabase, il nous suffira de faire
shp2pgsql -s 27582 -DI communes_lr.shp communes_lr | psql madatabase
Reportez-vous à la documentation de shp2pgsql pour les options ici utilisées. Nous noterons au passage que la région du Languedoc-Roussillon est composée de 1545 communes soit 1545 enregistrements dans notre table.
Pour avoir le maximum d'information sur la structure de cette table, je ne saurais vous conseiller la documentation en ligne sur le site de PostGIS. Comme dit dans ce document , c'est la table spatial_ref_sys de PostGIS qui contient les informations relatives aux divers systèmes de projection - table requise selon les spécifications de l'O.G.C (Open GIS Consortium). Excecutez la requête suivante par exemple pour voir les divers types de projections relatives à la France.
select srid,auth_name,auth_srid,srtext from spatial_ref_sys where srtext like '%France%'
La ligne qui nous intéresse est celle pour laquelle srid vaut 27582. Son champs srtext vaut
PROJCS["NTF (Paris) / France II",GEOGCS["NTF (Paris)",asting",600000](...)AUTHORITY["EPSG","27582"]]
Si l'on veut des détails supplémentaires, on pourra aussi faire
SELECT get_proj4_from_srid(27582);
qui renverra
get_proj4_from_srid ------------------------------------------------------------------------------------------------------------------------------------------------------------------------ +proj=lcc +lat_1=46.8 +lat_0=46.8 +lon_0=0 +k_0=0.99987742 +x_0=600000 +y_0=2200000 +a=6378249.2 +b=6356515 +towgs84=-168,-60,320,0,0,0,0 +pm=paris +units=m +no_defs (1 ligne)
Il faut utiliser la fonction DropGeometryColumn(). Cette fonction est une fonction surchargée avec PostgreSQL. On pourra par exemple utiliser la requête suivante
SELECT DropGeometryColumn('communes_lr','the_geom');qui renverra
dropgeometrycolumn ---------------------------------------------- public.communes_lr.the_geom effectively removed. (1 ligne )
Cette fonction nettoye effectivement la table geometry_columns, en effaçant l’enregistrement concernant la table communes_lr ici ainsi que la colonne géométrique de cette dernière. Les données atributaires (= non géométriques) sont maintenues.
La façon la plus simple de faire serait de faire
DROP TABLE ma_table;
Mais celà ne permet pas d'effacer les méta-données concernant ma_table dans geometry_columns. Imaginez la situation où vous voudriez réimporter les données et que vous ayant besoin de spécifier un SRID différent ou un non de colonne différent pour la colonne géométrique! Sinon vous risquez de vous retrouver avec le
Pour une telle situation, le mieux est de faire
SELECT DropGeometryTable('matable');On fera appel à cette fonction dans le cas où votre table se trouve dans le schéma courant de votre session cliente au serveur. En effet, cette fonction est une fonction surchargée, pour laquelle vous avez la fonction suivante aussi
SELECT DropGeometryTable('monschema','matable');Si votre table se trouve dans un schéma différent du schéma courant.
Dans le cas où les données ont déjà été importées et que lors de l'utilisation de shp2pgsql on a oublié d'utiliser l'option -s pour préciser le système de projection, PostGIS considère qu'il s'agit de données plannes du plan orthornormal. Il précise alors par défaut srid=-1. Ce qui peut-être contraignant par exemple si par la suite, nous soyons amenés à utiliser les fonctions Distance() ou Area2f() qui selon le système de projection peuvent donner des résultats faussées.
Pour préciser le système de projection, deux solutions possibles:
solution 1: recharger à nouveau les données en utilisant shp2pgsql avec les options respectives -s pour l'identifiant de projection et l'option -d qui permet d'effacer la table avant de recharger le fichier .shp d'origine. La commande sera donc
shp2pgsql -s 27582 -dDI communes_lr.shp communes_lr | psql madatabase
solution 2: garder les données déjà importées et modifier le srid à la volée. Pour cela, il faut avoir recours à la fonction UpdateGeometrySrid dont la synthaxe dans notre cas sera
SELECT UpdateGeometrySrid('communes_lr','the_geom',27582);
Dans les deux cas, les données sont mises à jours ainsi que les méta-données les concernant dans la table geometry_columns.
Avertissement
La fonction UpdateGeometrySrid() ne fait que mettre à jour comme précisé les méta-données des données spatiales MAIS EN AUCUN CAS, ELLE N'EFFECTUE AUCUN TRAVAIL DE REPROJECTION!!!
Le mieux ici est d'utiliser la fonction Transform(). Supposons par exemple que nous avons importé nos données en Lambert III Carto (27583) au lieu de Lambert II Etendu (27582)
BEGIN;
--
-- On met à jour l'identifiant du système de projection.
-- On passe donc du 27583 au 27582
--
SELECT UpdateGeometrySrid('communes_lr','the_geom',27582);
--
-- On met à jour la table
--
UPDATE communes_lr SET the_geom = foo.transform FROM (SELECT gid,Transform(the_geom,27582) from communes_lr ORDER BY gid ASC ) AS foo WHERE communes_lr. gid = foo.gid;
--
-- On se crée une vue de manière à ne pas se trainer
-- un ORDER BY avec nous sur la colonne "nom"
CREATE VIEW liste_communes_lr AS ( SELECT * from communes_lr ORDER BY NOM ASC );
--
-- Ok ... La transaction a réussie? On la clotûre.
--
END ;Je me suis ici permis de faire une simple vue sur la table communes_lr, de manière à ne pas me trainer un ORDER BY sur la colonne nom. Je rappelle au passage qu'un UPDATE sur une table ne fait référence à aucune notion d'ordre puisqu'en SQL, une table (relation) n'est pas un ensemble ordonné. D'où la raison personnelle ici, pourquoi j'utilise la vue liste_communes pour ne pas me trainer un ORDER BY si je veux la liste des noms de communes dans l'ordre croissant.
La table que nous avons créée contient pas moins de 1545 enregistrements. Normalement la création d'index spatiaux a lieu en ayant recours par exemple
CREATE INDEX [index_spatial_table] ON [table] USING gist([colonne_geometrique] gist_geometry_ops);
Or l'option -I de shp2pgsql permet de créer automatiquement un index spatial - suffixé _the_geom_gist - en pour chacun de ces enregistrements et évite d'avoir à se soucier de leur création par l'emploi de cette requête. Par exemple ici, cette option fait alors directement appel ici pour la table communes_lr à la requête d'indexation spatiale suivante
CREATE INDEX communes_lr_the_geom_gist ON communes_lr USING gist(the_geom gist_geometry_ops);
La création des index spatiaux peut s'avérer "gourmand". Pour que le planificateur de requêtes de PostgreSQL dispose des informations statistiques nécessaires et adéquates pour savoir quand avoir recours aux index spatiaux selon la fonction spatial demandée, il est nécessaire parfois de faire un VACUUM ANALYZE sur la base en cours
Nous reviendrons sur cet aspect plus tard. Pour résumer, nous dirons juste que à la suite d'une ou plusieurs importation(s) de données importante pour lesquelles il y a eu besoin de création d'index spatiaux Gist, il est recommandé d'utiliser la requête VACUUM ANALYZE
VACUUM ANALYZE
Note
Pour PostgreSQL 8.x.x, cette commande permet de collecter les informations statistiques de l'emploi des index spatiaux
Par définiton, je rappelle que l'étendue géographique d'un objet spatial dans une base de données est la plus petit fenêtre (=rectangle) qui le contienne. Ce dernier est défini par le quadruplet (Xmin,Ymin,Xmax,Ymax) . (Xmin,Ymin) (respectivement (Xmax,Ymax)) est le sommet inférieur gauche (respectivement le sommet supérieur droit) du rectangle dans tout système de projection orienté de gauche à droite horizontalement et de bas en haut vertivalement.
Pour connâitre ce quadruplet, la requête suivante
SELECT Xmin(foo.extent),
Ymin(foo.extent),
Xmax(foo.extent),
Ymax(foo.extent)
FROM
(SELECT Extent(the_geom) FROM communes_lr) AS foonous renvoit comme résultat
xmin | ymin | xmax | ymax --------+-------------+--------+------------- 547293 | 1703209.875 | 801423 | 1997767.125 (1 row)
Ce dernier implique donc que tous les objets de la colonne géométrique the_geom sont contenus dans le quadruplet ci-dessus obtenu.
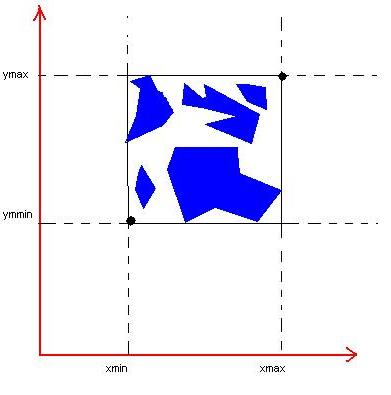
Note
Connaître l'étendue géographique peut s'avérer utile, notamment avec Mapserver dont les fichiers mapfiles possèdent un paramètre EXTENT qui correspond à l'étendue géogpraphique. Ici il s'agira de fournir ce quadruplet. Ce que j'appelle étendue géographique est aussi ce qu'on appelle emprise en SIG classique
Cette section suppose que l'emploi de MapServer vous soit familier. Je ne passerais pas ici en revue les divers fonctionnements de MapServer. Je profite de l'occasion juste pour détailler de quoi est composer la plus petite couche - LAYER au sens de MapServer - pour PostGIS. Je pars ici du principe que vous avez Apache, Php et PhpMapScript d'installés sur votre machine.
Note
Pour disposer de tous ces outils, le mieux est de recourir au paquet MS4W (MapServer For Windows) disponible sur le site http://www.maptools.org
Pour construire mon image sur les communes du Languedoc-Roussillon, le premier paramètre à fournir est bien l'EXTENT. Or selon une des dimensions de l'image que je me fixe (longueur ou hauteur), il me faut aussi savoir qu'elle sera la valeur de l'autre dimensions.
Il suffit pour cela d'effectuer une simple règle de trois que me donne la requête suivante inspirée de la requête de la section précédente:
SELECT
500*(abs(Ymax(foo.extent)-Ymin(foo.extent))/abs(Xmax(foo.extent)-Xmin(foo.extent)))
AS hauteur
FROM (SELECT Extent(the_geom) FROM communes_lr) AS fooqui me renvoie
hauteur ------------------ 579.540491087239 (1 ligne)
Pour afficher ma table communes_lr, ayant l'étendue géographique et la hauteur de l'image, je peux par exemple avoir comme mapfile appelée communes_lr.map
MAP
EXTENT 547293 1703209.875 801423 1997767.125
IMAGECOLOR 255 255 255
IMAGETYPE png
SIZE 500 579.540491087239
WEB
IMAGEPATH "c:/wamp/www/tutorial/tmp/"
IMAGEURL "/tutorial/tmp/"
END
#
# Couche des communes
#
LAYER
NAME "communes_lr"
CONNECTION "user=david dbname=madatabase host=localhost"
CONNECTIONTYPE POSTGIS
DATA "the_geom from communes_lr"
STATUS DEFAULT
TYPE POLYGON
CLASS
STYLE
COLOR 255 255 255
OUTLINECOLOR 0 0 0
END
END
END
ENDavec comme paramètres au niveau générale
EXTENT qui prend comme paramètres le quadruplet Xmin Ymin Xmax Ymax;
IMAGECOLOR prend comme valeur un RGB (Red Green Blue) pour définir le fond de couleur. Ici 255 255 255 pour avoir du blanc;
IMAGETYPE png pour préciser que l'image produite sera au format png. cela suppose que MapServer est été compilé avec l'option --with-png pr défaut comme OUTPUTFORMAT;
SIZE qui prend comme paramètres Longueur Hauteur
au niveau du WEB:
IMAGEPATH pour préciser le chemin d'accès absolue sur le disque où seront générées les images produites;
IMAGEURL url relative à la valeur donnée par IMAGEPATH
au niveau de la couche - LAYER - pour la table communes_lr
CONNECTION suivi des paramètres de connection à PostgreSQL;
CONNECTIONTYPE POSTGIS pour préciser qu'il s'agit d'une connection à une base de données PostGIS;
DATA dont la pseudo-valeur doit être "colonne_geometrique from table". On met donc ici "the_geom from communes_lr" sans le mot-clé SELECT.
TYPE qui précise la nature géométrique des objets à afficher. TYPE peut prendre la valuer POINT, LINE ou POLYGON.
le reste au niveau du CLASS/STYLE concerne l'habillage pour l'affichage des objets. Ici un contour noir (OUTLINECOLOR 0 0 0 et un intérieur blanc (COLOR 255 255 255)
Au niveau de php grâce à - l'extension phpmapscript si vous l'avez installé - pour générer l'image on peut utiliser le script suivant -
<html>
<body>
<?php
$sw_MapFile = "./mapfiles/communes_lr.map";
$map = ms_newMapObj( $sw_MapFile );
$image = $map->draw();
$image_url = $image->saveWebImage(MS_PNG,1,1,0);
echo "<IMG
BORDER=0
SRC='".$image_url."'
width='".$map->width."' height='".$map->height."'/>
<BR>";
?>
</body>
</html>On obtiendra ainsi le visuel suivant
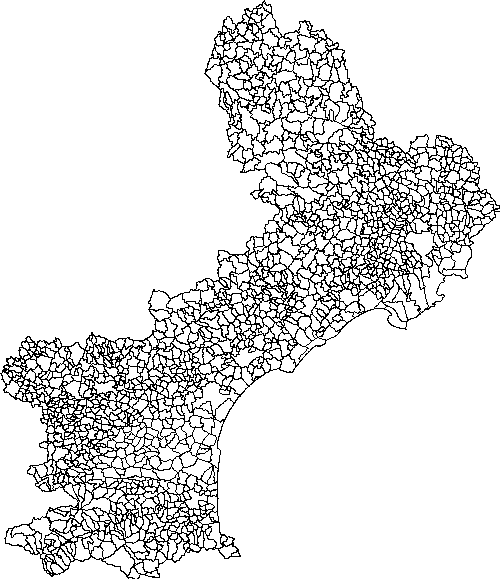
Dans le cas de certaines fonctions de PostGIS, parmi lesquelles nous pouvons citer Distance(); WithIn(), Intersects() [...]. ,il est parfois nécessaire selon la résultat escompté de les coupler à && := opérateur de chevauchement des étendues géographiques.
En effet, celui-ci sait tirer profit des index spatiaux - en interne de son implémentation, nous dirons qu'il les exploite-. Comme son nom l'indique, il teste si les étendues géographiques de deux objets géométriques A et B sechevauchent.
A titre d'exemple, pour avoir la liste des communes qui avoisines Montpellier, il s'agit simplement des communes dont la distance à Montpellier est nulle, ce qui sous-entend donc que leurs étendues géographiques se chevauchent- nous aurons recours à l'utilisation de l'opérateur && pour accélérer le temps nécessaire à la requête. D'où la requête suivante
SELECT b.nom FROM communes_lr a, communes_lr b
WHERE
a.nom LIKE 'MONTPELLIER'
AND
b.nom NOT LIKE 'MONTPELLIER'
AND
Distance(a.the_geom,b.the_geom)=0
AND
a.the_geom && b.the_geom
ORDER BY b.nomqui nous renvoit
nom -------------------------- CASTELNAU-LE-LEZ CLAPIERS GRABELS JUVIGNAC LATTES LAVERUNE MAUGUIO MONTFERRIER-SUR-LEZ SAINT-AUNES SAINT-CLEMENT-DE-RIVIERE SAINT-JEAN-DE-VEDAS (11 rows)
Sans l'utilisation ici de a.the_geom && b.the_geom, le temps demandé par la requête s'avère long - j'en témoigne pour 1544 enregistrements à tester! -.
Note
Il est également possible d'utiliser une fonction plus performante que la focntion Distance avec la condition Distance(A,B)=0 . On aurait pû avoir recours à la fonction Touches(A,B) qui permet de savoir si A et B se touchent puisqu'ici nous savons que les communes ne se "touchent" que par leur frontière
Pour mettre en évidence le temps mis par PostgreSQL pour exécuter la requête de la section précédente avec et sans la condition a.the_geom && b.the_geom, le mieux serait donc de reprendre la requête en la combinant aux mot-clés EXPLAIN ANALYZE
Note
Je n'exposerais pas ici les explications faisant appel au planificateur de tâches et à l'optimisateur de requêtes de PostgreSQL. Le mieux à mon sens est de se référer à la documentation officielle de PostgreSQL.
La requête suivante
EXPLAIN ANALYZE
SELECT b.nom FROM communes_lr a, communes_lr b
WHERE
a.nom LIKE 'MONTPELLIER'
AND
b.nom NOT LIKE 'MONTPELLIER'
AND
Distance(a.the_geom,b.the_geom)=0
AND
a.the_geom && b.the_geom
ORDER BY b.nomnous renvoit comme réponse
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=131.34..131.35 rows=1 width=32) (actual time=932.000..932.000 rows=11 loops=1)
Sort Key: b.nom
-> Nested Loop (cost=0.00..131.33 rows=1 width=32) (actual time=230.000..921.000 rows=11 loops=1)
Join Filter: (distance("outer".the_geom, "inner".the_geom) = 0::double precision)
-> Seq Scan on communes_lr a (cost=0.00..83.31 rows=8 width=32) (actual time=10.000..10.000 rows=1 loops=1)
Filter: ((nom)::text ~~ 'MONTPELLIER'::text)
-> Index Scan using communes_lr_the_geom_gist on communes_lr b (cost=0.00..5.98 rows=1 width=64) (actual time=10.000..20.000 rows=17 loops=1)
Index Cond: ("outer".the_geom && b.the_geom)
Filter: ((nom)::text !~~ 'MONTPELLIER'::text)
Total runtime: 932.000 ms
(10 lignes)soit un temps de 0.9 secondes (cf Total runtime: 932.000 ms). On voit bien d'après les résultats que l'index spatiaux est utilisé (cf "Index Scan using communes_lr_the_geom_gist on communes_lr", index créé automatiquement lors de l'importation des données par l'option -I de shp2pgsql.)
La même requête mais sans la contrainte
EXPLAIN ANALYZE
SELECT b.nom FROM communes_lr a, communes_lr b
WHERE
a.nom LIKE 'MONTPELLIER'
AND
b.nom NOT LIKE 'MONTPELLIER'
AND
Distance(a.the_geom,b.the_geom)=0
ORDER BY b.nomrenvoit comme résultat
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Sort (cost=476.08..476.23 rows=62 width=32) (actual time=152159.000..152159.000 rows=11 loops=1)
Sort Key: b.nom
-> Nested Loop (cost=83.32..474.23 rows=62 width=32) (actual time=74577.000..152159.000 rows=11 loops=1)
Join Filter: (distance("inner".the_geom, "outer".the_geom) = 0::double precision)
-> Seq Scan on communes_lr b (cost=0.00..83.31 rows=1538 width=64) (actual time=0.000..50.000 rows=1544 loops=1)
Filter: ((nom)::text !~~ 'MONTPELLIER'::text)
-> Materialize (cost=83.32..83.40 rows=8 width=32) (actual time=0.006..0.013 rows=1 loops=1544)
-> Seq Scan on communes_lr a (cost=0.00..83.31 rows=8 width=32) (actual time=10.000..20.000 rows=1 loops=1)
Filter: ((nom)::text ~~ 'MONTPELLIER'::text)
Total runtime: 152189.000 ms
(10 lignes)ce qui s'apparente à un temps d'exécution d'environ 2 minutes 30 (cf. Total runtime: 152189.000 ms). Ce qui est énorme!!! Ici, comme attendu il n'est pas fait usage des index spatiaux - par rapport à l'opérateur de chevauchement && -.
Ici par rapport au résultat avec l'opérateur && de la section précédente, la ligne pour la table 'communes_lr b'
-> Seq Scan on communes_lr b [... ] (actual time=0.000..50.000 rows=1544 loops=1) [...]
implique que 1544 enregistrements (cf rows=1544) de la table communes_lr ont été testés. Or si on enlève l'enregistrement qui correspond à celui de MONTPELLIER ('condition de la requête a.nom LIKE 'MONTPELLIER'), cela fait 1545 enregistrements. Soit le total d'enregistrement contenu dans la table communes_lr. Ce qui suppose donc que tous les enregistrements de la table ont été testés! Ce qui est justement l'opposé du bénéfice des index en bases de données.
En effet, avec l'opérateur && le coût de la table 'communes_lr b' s'élève à 17 enregistrements qui sont testés!
-> Index Scan using communes_lr_the_geom_gist on communes_lr b [...] (actual time=10.000..20.000 rows=17 loops=1)
Résultat qui exploite les index spatiaux!
On pourrait se contenter d'entrée de dire que la réponse directe serait de faire à la volée
CREATE TABLE communes_avoisinantes AS
(
SELECT b.* FROM communes_lr a, communes_lr b
WHERE
a.nom LIKE 'MONTPELLIER'
AND
Distance(a.the_geom,b.the_geom)=0
AND
a.the_geom && b.the_geom
ORDER BY b.nom
)Le premier souci qui se pose est que l'on n'a pas ici les méta-données concernant la nouvelle table référencées dans la table geometry_columns. On peut s'arrêter là si on n'a pas besoin d'utiliser cette table pour un affichage ultérieure avec MapServer.
Or dans le cas contraire d'un affichage avec MapServer, il est nécessaire que les métadonnées concernant la nouvelle table soient fournies dans la tables geometry_columns. En effet, quand il s'agit de données PostGIS à afficher, MapServer se sert de la fonction find_srid() qui elle s'appuie sur la table geometry_columns pour connaître l'identifiant de projection à utiliser.
Le mieux est alors d'avoir recours à quelques requêtes basique.s. On pourra essayer les requêtes successives décrites ici pour répondre à tous ces impératifs:
/*
On commence par effacer la table communes_avoisinantes
si elle exite déjà.
Ceci au cas où nous serions amenés à recharger ce fichier.
On peut aussi utiliser la commande: DROP TABLE communes_avoisinantes
*/
SELECT drop_table_if_exists('communes_avoisinantes',false);
/*
On crée une table vide communes_avoisinantes
pour cela, il suffit de demander de retourner la table communes_lr avec 0 lignes.
On obtient ainsi la même structure que la table communes_lr
*/
CREATE TABLE communes_avoisinantes AS
SELECT * FROM communes_lr LIMIT 0;
/*
On efface la colonne geometrique 'the_geom' dans la table communes_avoisinantes
car pour l'instant celle-ci n'est par référencée comme il faut
dans la table geometry_columns
*/
ALTER TABLE communes_avoisinantes DROP COLUMN the_geom;
/*
On ajoute la colonne 'the_geom' proprement en utilisant AddGeometryColumn()
Ici, on joue le jeu que l'on ne connaît de la table
communes_lr que son nom. On ignore donc le type
géométrique, son srid...Toutes ces informations sont stockées
dans la table geometry_columns.
*/
SELECT AddGeometryColumn('communes_avoisinantes'::varchar,
foo.f_geometry_column::varchar,
foo.srid::integer,
foo.type::varchar,
foo.coord_dimension::integer
)
FROM (
SELECT * FROM geometry_columns WHERE
f_table_name LIKE 'communes_lr'
) AS foo;
/*
On insère maintenant les données attendues dans la table
*/
INSERT INTO communes_avoisinantes
(
SELECT b.* FROM communes_lr a, communes_lr b
WHERE
a.nom LIKE 'MONTPELLIER'
AND
Distance(a.the_geom,b.the_geom)=0
AND
a.the_geom && b.the_geom
ORDER BY b.nom
);Note
A partir de l'étude réalisée pour la table communes_lr, il est alors aisé de pouvoir visualiser le contenu de cette table dans MapServer.
Nous ici pour cela utiliser la table communes_avoisinantes. Toutes ces résultats peuvent être obtenue grâce à la requête suivante:
SELECT fooo.nom,
AsText(Intersection(foo.the_geom,fooo.the_geom)),
AsSVG(Intersection(foo.the_geom,fooo.the_geom))
FROM (
SELECT the_geom FROM communes_avoisinantes
WHERE nom LIKE 'MONTPELLIER'
) AS foo
,
(
SELECT nom,the_geom FROM communes_avoisinantes
WHERE nom LIKE 'JUVIGNAC' OR nom LIKE 'LATTES'
) AS fooo ;ou sinon la requête suivante possible
SELECT b.nom,
AsText(Intersection(a.the_geom,b.the_geom)),
AsSVG(Intersection(a.the_geom,b.the_geom))
FROM communes_avoisinantes a,communes_avoisinantes b
WHERE a.nom='MONTPELLIER'
AND (b.nom='LATTES' OR b.nom='JUVIGNAC');Je n'afficherais pas ici les résultats obtenus car ces derniers prennent trop de place en affichage. Je me contenterais de les résumés ainsi
nom | intersection | assvg ----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ JUVIGNAC | MULTILINESTRING((719652.990195505 1844379.97900231,[...]718841.967178608 1849682.04627155)) | M 719652.9901955052 -1844379.9790023109 [...] 718841.96717860829 -1849682.0462715544 LATTES | MULTILINESTRING((729577.052318637 1845119.97019685,[...],723311.014479515 1841729.00265142))| M 729577.05231863656 -1845119.9701968494[...] 723311.01447951456 -1841729.0026514169 (2 lignes)
Au niveau de l'affichage on obtient
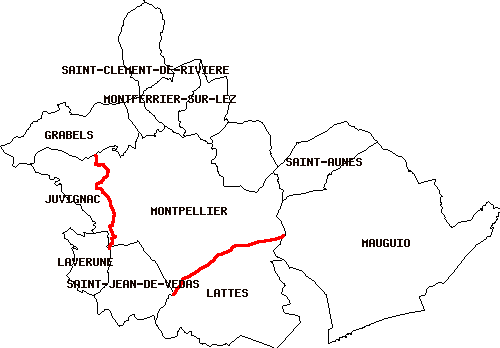
Il suiif par exemple d'utiliser la fonction Min() et Area2d() pour avoir comme requête:
SELECT nom FROM communes_avoisinantes
WHERE Area2d(the_geom) = (SELECT Min(Area2d(the_geom)) FROM communes_avoisinantes)nous renvoyant comme réponse
nom ---------- LAVERUNE (1 row)
Le visuel sera alors le suivant
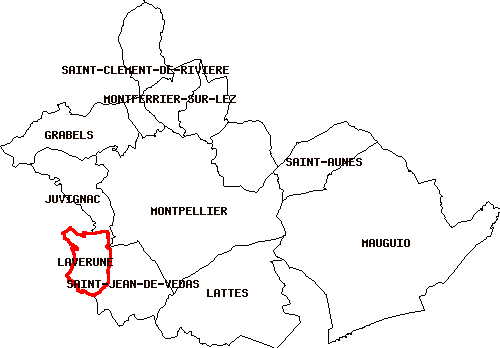
Je fournis ci après la mapfile qui permet d'afficher la table communes_avoisinantes, ainsi que les deux requêtes précédemment poser. Il est à noter surtout la formulation des requêtes - paramètre DATA - pour pouvoir afficher les objets attendues.
MAP
EXTENT 713413.9375 1838659.875 741999.0625 1858572.125
FONTSET "c:\wamp\www\tutorial\etc\fonts.txt"
SYMBOLSET "c:\wamp\www\tutorial\etc\symbols.sym"
IMAGECOLOR 255 255 255
IMAGETYPE png
SIZE 500 348.297409929115
# STATUS ON
WEB
IMAGEPATH "c:/wamp/www/tutorial/tmp/"
IMAGEURL "/tutorial/tmp/"
END
#===============================================================================
# La table communes_avoisinantes
#===============================================================================
LAYER
NAME "communes_avoisinantes"
CONNECTION "user=david dbname=madatabase host=localhost"
CONNECTIONTYPE POSTGIS
DATA "the_geom from communes_avoisinantes"
STATUS DEFAULT
TYPE POLYGON
LABELITEM "nom"
CLASS
LABEL
SIZE MEDIUM
TYPE BITMAP
BUFFER 0
COLOR 22 8 3
FORCE FALSE
MINDISTANCE -1
MINFEATURESIZE -1
OFFSET 0 0
PARTIALS TRUE
POSITION CC
END
STYLE
COLOR 255 255 255
OUTLINECOLOR 0 0 0
END
END
END
#===============================================================================
# Requête 1: Intersection entre Montpellier et les communes de LATTES et JUVIGNAC
#===============================================================================
LAYER
NAME "requete_1"
CONNECTION "user=david dbname=madatabase host=localhost"
CONNECTIONTYPE POSTGIS
DATA "intersection from
(SELECT
intersection(foo.the_geom,fooo.the_geom),fooo.nom,fooo.gid
FROM (
SELECT * FROM communes_avoisinantes
WHERE nom LIKE 'MONTPELLIER'
) AS foo
,
(
SELECT * FROM communes_avoisinantes
WHERE nom LIKE 'JUVIGNAC' OR nom LIKE 'LATTES'
) AS fooo
)AS uo USING UNIQUE gid USING SRID=27582"
STATUS OFF
TYPE LINE
LABELITEM "nom"
CLASS
STYLE
OUTLINECOLOR 255 0 0
SIZE 3
SYMBOL "circle"
END
END
END
#===============================================================================
# Requête 2: La plus petite commune autour de Montpellier
#===============================================================================
LAYER
NAME "requete_2"
CONNECTION "user=david dbname=madatabase host=localhost"
CONNECTIONTYPE POSTGIS
DATA "the_geom from
(SELECT the_geom,nom,gid FROM communes_avoisinantes
WHERE Area2d(the_geom) = (SELECT Min(Area2d(the_geom)) FROM
communes_avoisinantes))AS uo USING UNIQUE gid USING SRID=27582"
STATUS DEFAULT
TYPE LINE
LABELITEM "nom"
CLASS
STYLE
OUTLINECOLOR 255 0 0
SIZE 3
SYMBOL "circle"
END
END
END
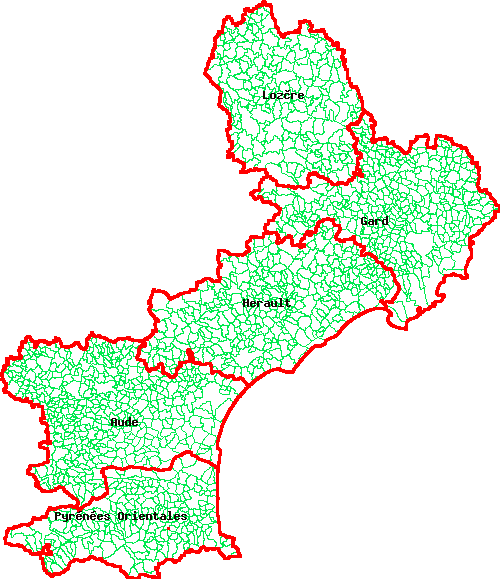
ENDLa région du Languedoc-Roussillon est composée de 5 départements dont voici la liste
Aude 11;
Hérault 34;
Gard 30;
Lozère 48;
Pyrénées Orientales 66.
Normalement lorsqu'on dispose des limites communales d'une région on doit aussi pouvoir disposer des limites départementales de cette dernière. Nous partirons ici du principe que nous ne disposons que de la table communes_lr. C'est à partir de cette table que nous allons créer nos limites départementales. Nous allons mettre les contours départementaux dans une table departements_lr ayant la structure suivante
CREATE TABLE departements_lr(id serial,nom text,numero integer)WITH OIDS;
où nom désignera le nom du département et numero son numéro. Comme pour l'instant, je ne sais pas quel est la la nature des objets géométrique, je fais juste
SELECT AddGeometryColumn('departements_lr','the_geom',27582,'GEOMETRY',2);Avant de remplir ma table, je dois préciser que je dois pour la suite faire des requêtes du genre
INSERT INTO departements_lr ( select 1 as id ,'Herault':: text as nom ,34 as numero , geomunion (the_geom) as the_geom from communes_lr where insee like '34% ' );
insertion que je vais utiliser 5 fois. Il apparaît clairement ici que j'utilise la condition "where insee like 'constante%'" . Or PostgreSQL pour les champs de colonne pour lesquels on exige un modèle de recherche du style "WHERE mon_champs LIKE 'chaine_de_caractère_fixe%'" sait tirer profit des index pour ce genre de modèle. Comme la locale de notre installation n'est pas en 'C', il va falloir utiliser un autre type de modèle que le B-Tree proposé par défaut par PostgreSQL Avant toute chose, je dois donc connaître le type de données du champs insee de ma table communes_lr :
SELECT column_name,data_type FROM information_schema.columns WHERE table_name ='communes_lr' AND table_schema ='public' AND column_name = 'insee' AND table_catalog = 'madatabase';
qui me renvoit
column_name | data_type
-------------+------------------
insee | character varying
(1 ligne )Je crée donc l'index adéquate sur la colonne insee qui est de type varchar de ma table communes_lr en faisant
CREATE INDEX communes_lr_insee ON communes_lr(insee varchar_pattern_ops);
Vérifions bien que l'index sera utilisé sur la requête d'insertion donnée avant
EXPLAIN ANALYZE SELECT 1 AS id ,' Herault ':: text AS nom ,34 AS numero , geomunion (the_geom) AS the_geom from communes_lr WHERE insee LIKE '34%'
qui me renvoit
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=71.00..71.01 rows=1 width=3957) (actual time=43989.893..43989.898 rows=1 loops=1)
-> Bitmap Heap Scan on communes_lr (cost=4.43..70.40 rows=238 width=3957) (actual time=0.163..5.447 rows=343 loops=1)
Filter: ((insee)::text ~~ '34%'::text)
-> Bitmap Index Scan on communes_lr_insee (cost=0.00..4.43 rows=238 width=0) (actual time=0.138..0.138 rows=343 loops=1)
Index Cond: (((insee)::text ~>=~ '34'::character varying) AND ((insee)::text ~<~ '35'::character varying))
Total runtime: 44001.960 ms
(6 lignes)La portion de texte "Bitmap Index Scan on communes_lr_insee" met en évidence l'utilisation de l'index communes_lr_insee dans cette requête pour le modèle de recherche WHERE mon_champs like 'chaine_constante%';
Note
Ici ce qui coûte cher c'est la fonction GeomUnion() pour faire la réunion géométrique. Certes il est vrai que pour une table de 1545 lignes, celà peut paraître dérisoire que de faire un index. Mon but ici est de montrer comment créer l'index lorsque la local n'est par en 'C' pour la CLAUSE WHERE énoncée ici. Je ne dis pas non plus qu'il faut impérativement créer un index pour tous les champs mais si la table avait contenu par exemple au moins 20000 lignes celà peut s'avérer utile.
Je remplis maintenant la table pour tous les départements
INSERT INTO departements_lr ( select 1 as id,'Herault'::text as nom,34 as numero,geomunion(the_geom) as the_geom from communes_lr where insee like '34%' ); INSERT INTO departements_lr ( select 2 as id,'Gard'::text as nom,30 as numero,geomunion(the_geom) as the_geom from communes_lr where insee like '30%' ); INSERT INTO departements_lr ( select 3 as id,'Lozère'::text as nom,48 as numero,geomunion(the_geom) as the_geom from communes_lr where insee like '48%' ); INSERT INTO departements_lr ( select 4 as id,'Aude'::text as nom,11 as numero,geomunion(the_geom) as the_geom from communes_lr where insee like '11%' ); INSERT INTO departements_lr ( select 5 as id,'Pyrénées Orientales'::text as nom,66 as numero,geomunion(the_geom) as the_geom from communes_lr where insee like '66%' );
Je ne cache pas qu'ici le peuplement de la table m'a pris 7 à 8 minutes quand même! Compréhensible dans le sens où faire/calculer la réunion géométrique de plusieurs objets géométriques demande du temps.
Pour savoir quel est le type de données géométriques adéquates, il faut utiliser la commande
select nom,geometrytype(the_geom) from departements_lr
qui me renvoit
nom | geometrytype ---------------------+-------------- Herault | MULTIPOLYGON Gard | POLYGON Lozère | POLYGON Aude | POLYGON Pyrénées Orientales | POLYGON (5 lignes)
Je réordonne les tables geometry_columns en mettant le type de departements_lr à MULTIPOLYGON et je convertis tous les departements en MULTIPOLYGON grâce à la fonction Multi() de PostGIS.
update geometry_columns set type='MULTIPOLYGON' where f_table_name='departements_lr'; update departements_lr set the_geom=(multi(the_geom::text));
il faut ensuite créer l'index spatial sur la table departements_lr et faire un vacuum analyze sur la base.
create index departements_lr_the_geom_gist on departements_lr using gist(the_geom gist_geometry_ops); vacuum analyze;
Au niveau de la mapfile, il faudrait ajouter le layer suivant
#==========================================================
# Couche des départements
#==========================================================
LAYER
NAME "departements_lr"
CONNECTION "user=david dbname=madatabase host=localhost"
CONNECTIONTYPE POSTGIS
DATA "the_geom from departements_lr"
STATUS DEFAULT
TYPE POLYGON
LABELITEM "nom"
CLASS
LABEL
SIZE MEDIUM
TYPE BITMAP
BUFFER 0
COLOR 22 8 3
FORCE FALSE
MINDISTANCE -1
MINFEATURESIZE -1
OFFSET 0 0
PARTIALS TRUE
POSITION CC
END
STYLE
OUTLINECOLOR 255 0 0
SIZE 3
SYMBOL "circle"
END
END
ENDAI niveau de l'afffichage, on obtient alors
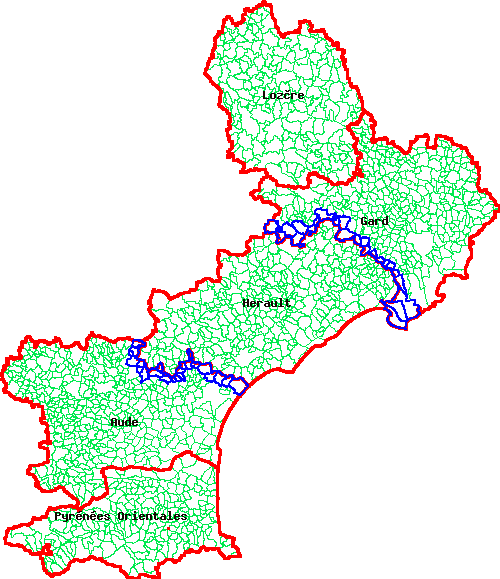
Comme je sais ici que les communes des départements du Gard et de l'Aude commencent respectivement par 30 et 11, je vais pour cela utiliser la fonction Touches de PostGIS.
Au niveau de la mapfile, je ferais simplement
#==========================================================
# requete
#==========================================================
LAYER
NAME "requete"
CONNECTION "user=david dbname=madatabase host=localhost"
CONNECTIONTYPE POSTGIS
DATA "the_geom from (
select c.* from departements_lr d,communes_lr c
where touches(d.the_geom,c.the_geom)
and d.the_geom && c.the_geom
and d.nom='Herault'
and (c.insee like '11%' or c.insee like '30%')
) as foo USING UNIQUE gid USING SRID=27582"
STATUS DEFAULT
TYPE POLYGON
CLASS
LABEL
SIZE MEDIUM
TYPE BITMAP
BUFFER 0
COLOR 22 8 3
FORCE FALSE
MINDISTANCE -1
MINFEATURESIZE -1
OFFSET 0 0
PARTIALS TRUE
POSITION CC
END
STYLE
OUTLINECOLOR 0 0 255
SIZE 2
SYMBOL "circle"
END
END
END
Au niveau de l'affichage avec MapServer, j'obtiens
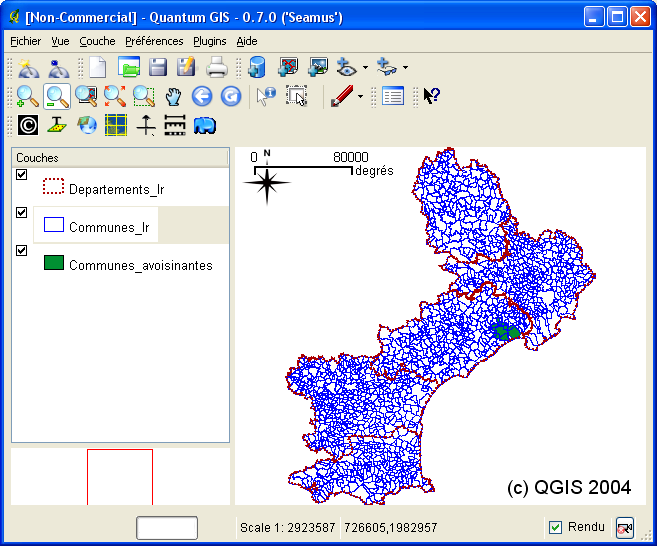
A la rédaction de ce document, depuis le 7 septembre 2005 la version 0.7 de QGIS est disponible pour diverses plateformes dont Windows. PostGIS 1.0.X est accepté par ce viewer - qui est bien plus qu' un viewer! -. QGIS 0.7 est disponible à cette adresse http://qgis.org
Travaillant personnellement sous Linux, je me permettrais ici uniquement de citer un exemples de projet réalisé sous GNU/Linux pour lequel on souhaiterait savoir à l'échelle du 25000ème quel serait pour un polygone rattaché à un point dans la ville de DIJON le meilleur format possible allant du A4 Portrait au A0 Paysage.
Sur l'image suivante, une croix rouge précise que le format est déconseillé, alors que le symbole en vert propose que le format étudié est possible. On cherche à savoir par exemple si le polygone en vert (voir les images) débordera ou non de la carte.
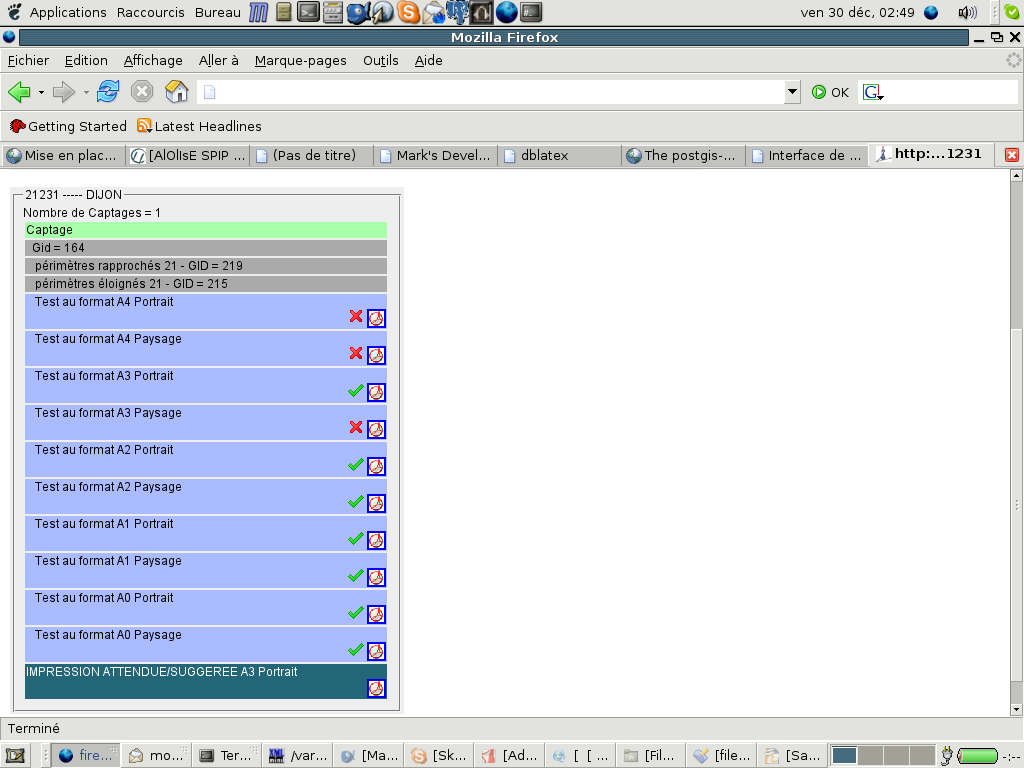
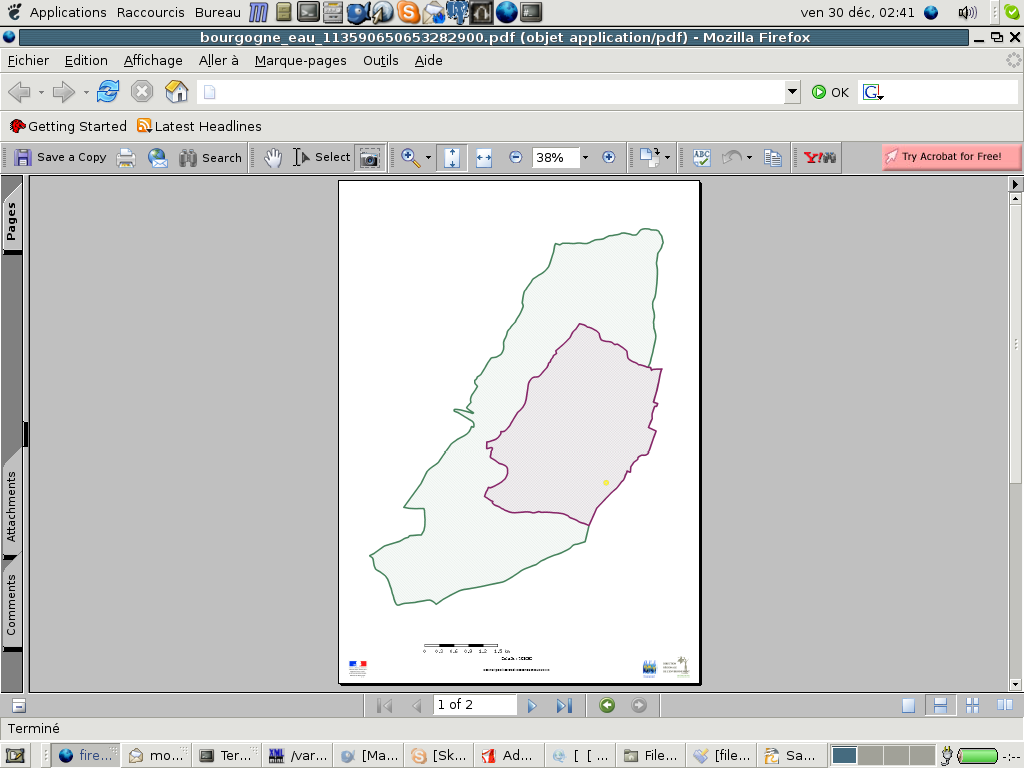
D'après cette image, on s'aperçoit donc que le format A4 Portrait ne convient pas:
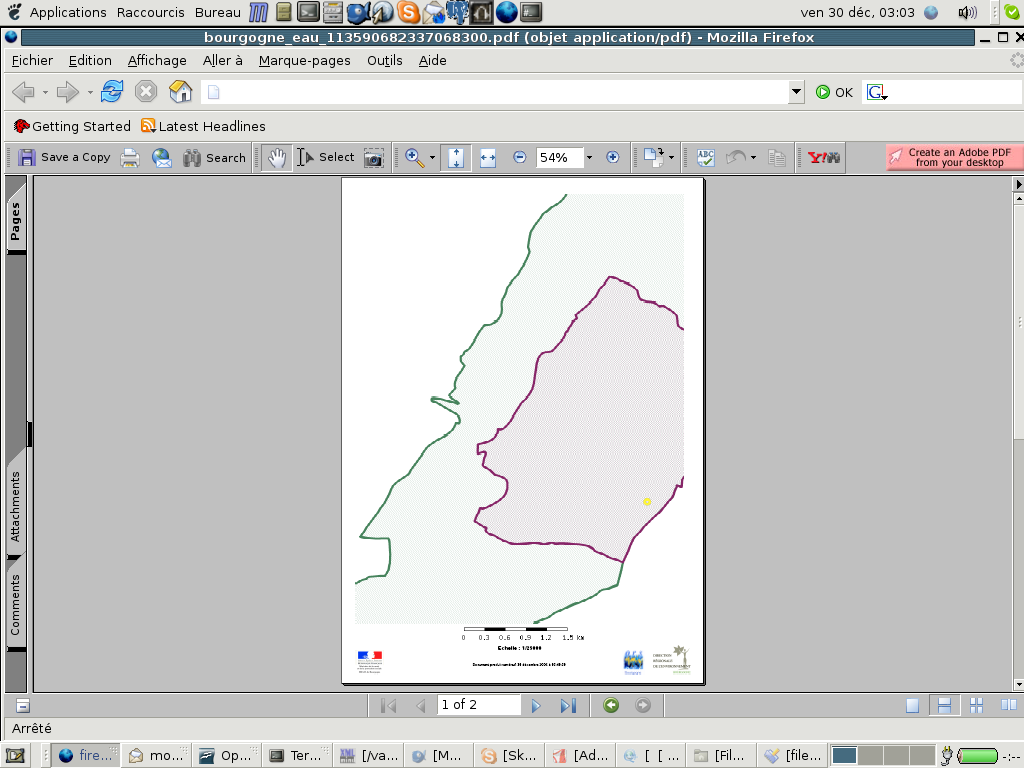
alors que le format A3 convient parfaitement
En utilisant le wrapper PHP pour PostGIS réalisé par Paul SCOTT, un extrait de code possible pour traiter un tel projet serait par exemple:
/**
* Function IsAGoodFormat
* Permet de tester si pour un format d'impressions sera parfait
* selon le captage en question
*/
function IsAGoodFormat($Connexion,
$mapfile,
$gidcaptage,
$couches,
$gids,
$Dept,
$format
)
{
//
// Preparation des requetes
//
//echo $couches;echo $gids;
$tables = array();$tables = explode(",",$couches);
$tables_gid = array();$tables_gid = explode(",",$gids);//echo count($tables);
if ( (count($tables)==1) && (count($tables_gid)==1) )
{
$result= 0;
}
else
{//Debut du traitement general
if (count($tables)==2)
{
$table = $tables[1];
$Requete = "select the_geom from ".$table." where ".$table.".gid=".$tables_gid[1];
}
else
{
$Requete = "";
for($ItTable=1;$ItTable<count($tables);$ItTable++)
{// Debut de la boucle general
$table = $tables[$ItTable];
$gid = $tables_gid[$ItTable];
$Requete .= "(select the_geom from ".$table." where gid =".$gid.") union ";
}// Fin de la boucle general
$Requete = substr($Requete,0,strlen($Requete)-7);
}
//echo $format." --- ".$Requete."<br>";
$Connexion->exec("SELECT Xmin(foo.extent),Ymin(foo.extent),Xmax(foo.extent),Ymax(foo.extent)
FROM
(select extent(fo.the_geom) from (".$Requete.") as fo) AS foo");
if($Connexion->numRows() > 0)
{
$Connexion->nextRow();$rs = $Connexion->fobject();
$sw_MapFile = $mapfile;
$goMap = ms_newMapObj( $sw_MapFile );
$goMap->setextent($rs->xmin,$rs->ymin,$rs->xmax,$rs->ymax);
$goMap->set("width",GetImageWidth($format));$goMap->set("height",GetImageHeight($format));
$oPixelPos = ms_newpointobj();
$WidthPix = 400;
$HeightPix = 300;
$MapScale = GetScale();
$oPixelPos->setxy($WidthPix/2, $HeightPix/2);
$oGeorefExt = ms_newrectobj();
$oGeorefExt->setextent($rs->xmin,$rs->ymin,$rs->xmax,$rs->ymax);
$zoomc = $goMap->zoomscale($MapScale, $oPixelPos, $WidthPix, $HeightPix, $oGeorefExt);
$Connexion->exec( "select GeomFromText('MULTIPOINT(".$rs->xmin." ".$rs->ymin.",".$rs->xmax." ".$rs->ymax.")',-1) @ GeomFromText('MULTIPOINT(".$goMap->extent->minx." ".$goMap->extent->miny.",".$goMap->extent->maxx." ".$goMap->extent->maxy.")',-1) as affichage");
$Connexion->nextRow();$rs = $Connexion->fobject();
$result = (($rs->affichage=="t")? 1:0);
$GoodMap = $goMap;
}
}// Fin du traitement general
return array($result,$GoodMap);
}
Ici nous exposons un second cas auquel nous sommes parfois confronté6
Supposons que dans nous disposions d'une table contenant les tronçons des rivière s, canaux, fleuves (...) traversent la DROME (26). Nous appelerons cette table troncons_rivieres_26. Nous souhaiterions pouvoir réunifier les tronçons de manière à pouvoir reconstituer le réseau hydrolique de la drôme. Ici nous ne ferons pas de distinction entre les diverses natures des tronçons. Je veux dire par là que nous ne tiendrons pas contre à savoir si un tronçon fait parti d'une rivière, canal etc...
Dans la table troncons_rivieres_26, nous avons à notre disposions deux champs toponyme et cgenelin qui nous permette de réunifier les tronçons en fonction du toponyme qui les regroupent entre eux. Par exemple, nous pourrions avoir
SELECT DISTINCT count(*),toponyme,cgenelin FROM troncons_rivieres_26 GROUP BY 2,3 ORDER BY 1 DESC
qui nous renverra
count | toponyme | cgenelin -------+--------------------------------------+---------- ... | .................. | ..... 172 | fleuve le rhône | XXXXX 132 | rivière la roanne | XXXXX 129 | rivière la lyonne | XXXXX 127 | rivière l'isère | XXXXX 116 | rivière l'ouvèze | XXXXX 116 | ruisseau le chalon | XXXXX 112 | rivière la galaure | XXXXX 111 | rivière la méouge | XXXXX ... | .................. | .....
On voit par exemple ici que le fleuve le rhône qui traverse la drôme est contitué de 172 tronçons, la roanne de 132 etc...etc...
Notre but ici est donc de reconstituer le réseau hydrologique à partir de ces deux champs
Nous ferons appel ici à une transaction de PostgrSQL
BEGIN;
--
-- Début de la transaction
--
-- select dropgeometrytable('reseau_hydro_26');
--
-- Sur la table reseau_hydro_26 à créer, activation des oids
--
SET default_with_oids=true;
--
-- Création de la table en récupérant
-- le toponyme, le cgenelin et en faisant
-- la réunion géométrique des tronçons
-- grâce à geomunion()
--
CREATE TABLE reseau_hydro_26 AS
(SELECT DISTINCT toponyme,cgenelin,geomunion(the_geom) FROM troncons_rivieres_26 GROUP BY toponyme,cgenelin);
--
-- Ajout de la colonne géométrique
--
SELECT addgeometrycolumn('reseau_hydro_26','the_geom',-1,'MULTILINESTRING',2);
--
-- La colonne the_geom est vide,
-- on la met à jour en la remplissant par la colonne geomunion
--
UPDATE reseau_hydro_26 SET the_geom=geomunion;
--
-- Nous n'avons plus besoin de la colonne geomunion
--
ALTER TABLE reseau_hydro_26 DROP COLUMN geomunion;
--
-- fin de la transaction
--
END;On obtiendra alors le réseau comme sur l'image suivante
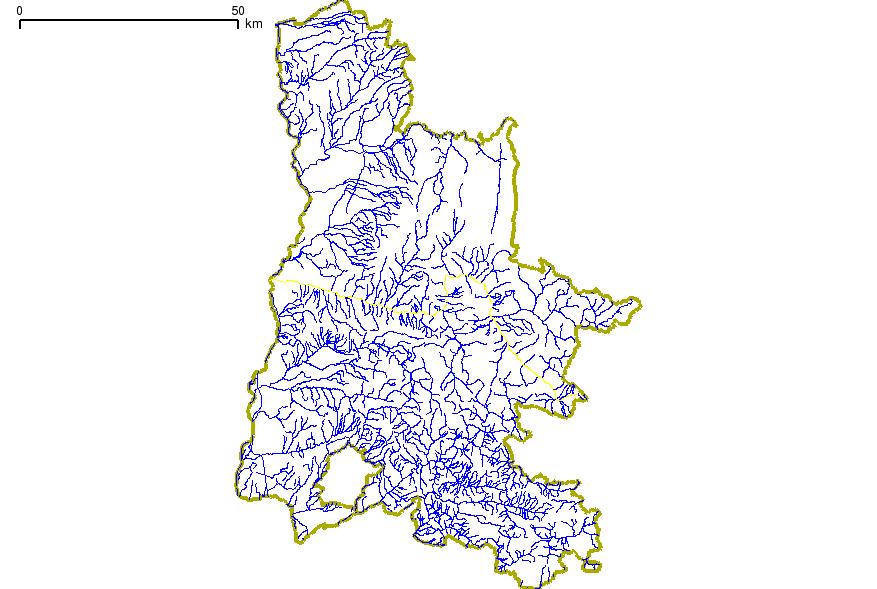
Puisque notre table est créée, On va essayer ici d'ajouter des questions utiles de PostGIS qui permettent de faire le tour sur d'autre fonctions possibles
Nous utiliserons ici la fonction NumGeometries() qui peut-être utilisée car les objets sont de type MULTI.
SELECT toponyme,numgeometries(the_geom) FROM reseau_hydro_26 WHERE topohy_ign='drôme, la (rivière)';
qui nous renverra
toponyme | numgeometries ---------------------+--------------- drôme, la (rivière) | 206 (1 ligne)
La "drôme" est donc la réunion géométrique de 206 tronçons.
Avertissement
L'utilisation de la fonction NumGeometries() ne peut se faire que si l'on s'est d'avance que la nature de l'objet à interroger est de type MULTI (POLYGON, LINESTRING ou POINT).